
问答社区
ChatGLM-6B: An Open GLM-4 开源模型和API | 开源双语对话语言模型
GLM-4 开源模型和API
我们已经发布最新的 GLM-4 大语言对话模型,该模型在多个指标上有了新的突破,您可以在以下两个渠道体验我们的最新模型。
-
GLM-4 开源模型 我们已经开源了 GLM-4-9B 系列模型,在各项指标的ce是上有明显提升,欢迎尝试。
-
智谱清言 体验最新版 GLM-4,包括 GLMs,All tools等功能。
-
API平台 新一代 API 平台已经上线,您可以直接在 API 平台上体验
GLM-4-0520、GLM-4-air、GLM-4-airx、GLM-4-flash、GLM-4、GLM-3-Turbo、CharacterGLM-3,CogView-3等新模型。 其中GLM-4、GLM-3-Turbo两个模型支持了System Prompt、Function Call、Retrieval、Web_Search等新功能,欢迎体验。 -
GLM-4 API 开源教程 GLM-4 API教程和基础应用,欢迎尝试。 API相关问题可以在本开源教程疑问,或者使用 GLM-4 API AI助手 来获得常见问题的帮助。
介绍
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答,更多信息请参考我们的博客。欢迎通过 chatglm.cn 体验更大规模的 ChatGLM 模型。
为了方便下游开发者针对自己的应用场景定制模型,我们同时实现了基于 P-Tuning v2 的高效参数微调方法 (使用指南) ,INT4 量化级别下最低只需 7GB 显存即可启动微调。
ChatGLM-6B 权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
ChatGLM-6B 开源模型旨在与开源社区一起推动大模型技术发展,恳请开发者和大家遵守开源协议,勿将开源模型和代码及基于开源项目产生的衍生物用于任何可能给国家和社会带来危害的用途以及用于任何未经过安全评估和备案的服务。目前,本项目团队未基于 ChatGLM-6B 开发任何应用,包括网页端、安卓、苹果 iOS 及 Windows App 等应用。
尽管模型在训练的各个阶段都尽力确保数据的合规性和准确性,但由于 ChatGLM-6B 模型规模较小,且模型受概率随机性因素影响,无法保证输出内容的准确性,且模型易被误导。本项目不承担开源模型和代码导致的数据安全、舆情风险或发生任何模型被误导、滥用、传播、不当利用而产生的风险和责任。
更新信息
[2023/07/25] 发布 CodeGeeX2 ,基于 ChatGLM2-6B 的代码生成模型,代码能力全面提升,更多特性包括:
- 更强大的代码能力:CodeGeeX2-6B 进一步经过了 600B 代码数据预训练,相比 CodeGeeX 一代模型,在代码能力上全面提升,HumanEval-X 评测集的六种编程语言均大幅提升 (Python +57%, C++ +71%, Java +54%, JavaScript +83%, Go +56%, Rust +321%),在Python上达到 35.9% 的 Pass@1 一次通过率,超越规模更大的 StarCoder-15B。
- 更优秀的模型特性:继承 ChatGLM2-6B 模型特性,CodeGeeX2-6B 更好支持中英文输入,支持最大 8192 序列长度,推理速度较一代 大幅提升,量化后仅需6GB显存即可运行,支持轻量级本地化部署。
- 更全面的AI编程助手:CodeGeeX插件(VS Code, Jetbrains)后端升级,支持超过100种编程语言,新增上下文补全、跨文件补全等实用功能。结合 Ask CodeGeeX 交互式AI编程助手,支持中英文对话解决各种编程问题,包括且不限于代码解释、代码翻译、代码纠错、文档生成等,帮助程序员更高效开发。
[2023/06/25] 发布 ChatGLM2-6B,ChatGLM-6B 的升级版本,在保留了了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
- 更强大的性能:基于 ChatGLM 初代模型的开发经验,我们全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
- 更长的上下文:基于 FlashAttention 技术,我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。但当前版本的 ChatGLM2-6B 对单轮超长文档的理解能力有限,我们会在后续迭代升级中着重进行优化。
- 更高效的推理:基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
更多信息参见 ChatGLM2-6B。
[2023/06/14] 发布 WebGLM,一项被接受于KDD 2023的研究工作,支持利用网络信息生成带有准确引用的长回答。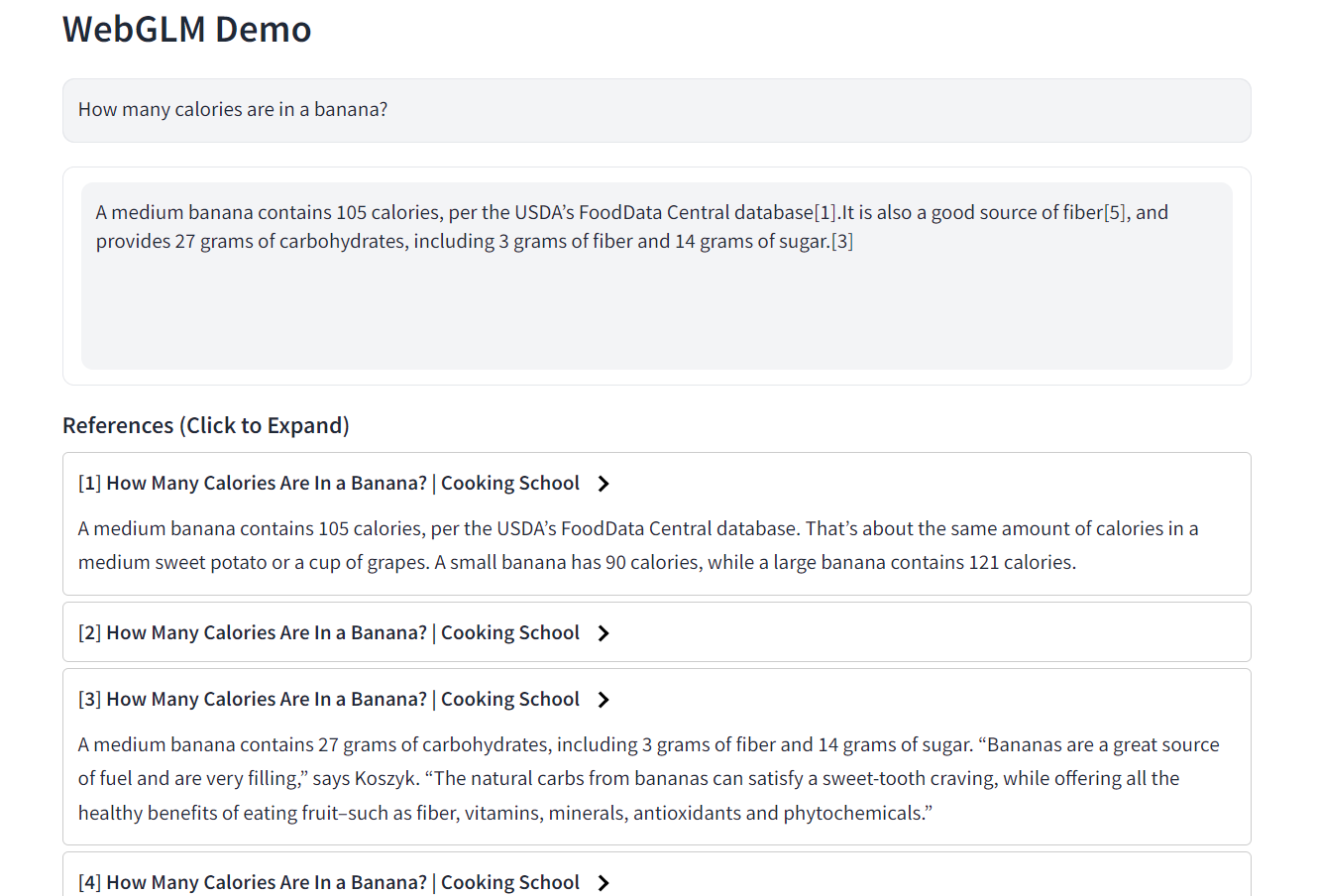
[2023/05/17] 发布 VisualGLM-6B,一个支持图像理解的多模态对话语言模型。
可以通过仓库中的 cli_demo_vision.py 和 web_demo_vision.py 来运行命令行和网页 Demo。注意 VisualGLM-6B 需要额外安装 SwissArmyTransformer 和 torchvision。更多信息参见 VisualGLM-6B。
[2023/05/15] 更新 v1.1 版本 checkpoint,训练数据增加英文指令微调数据以平衡中英文数据比例,解决英文回答中夹杂中文词语的现象。
使用方式
硬件需求
| 量化等级 | 最低 GPU 显存(推理) | 最低 GPU 显存(高效参数微调) |
|---|---|---|
| FP16(无量化) | 13 GB | 14 GB |
| INT8 | 8 GB | 9 GB |
| INT4 | 6 GB | 7 GB |
环境安装:
使用 pip 安装依赖:pip install -r requirements.txt,其中 transformers 库版本推荐为 4.27.1,但理论上不低于 4.23.1 即可。
此外,如果需要在 cpu 上运行量化后的模型,还需要安装 gcc 与 openmp。多数 Linux 发行版默认已安装。对于 Windows ,可在安装 TDM-GCC 时勾选 openmp。 Windows 测试环境 gcc 版本为 TDM-GCC 10.3.0, Linux 为 gcc 11.3.0。在 MacOS 上请参考。
代码调用
可以通过如下代码调用 ChatGLM-6B 模型来生成对话:
>>> from transformers import AutoTokenizer, AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
>>> model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
>>> model = model.eval()
>>> response, history = model.chat(tokenizer, "你好", history=[])
>>> print(response)
你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。
>>> response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
>>> print(response)
晚上睡不着可能会让你感到焦虑或不舒服,但以下是一些可以帮助你入睡的方法:
1. 制定规律的睡眠时间表:保持规律的睡眠时间表可以帮助你建立健康的睡眠习惯,使你更容易入睡。尽量在每天的相同时间上床,并在同一时间起床。
2. 创造一个舒适的睡眠环境:确保睡眠环境舒适,安静,黑暗且温度适宜。可以使用舒适的床上用品,并保持房间通风。
3. 放松身心:在睡前做些放松的活动,例如泡个热水澡,听些轻柔的音乐,阅读一些有趣的书籍等,有助于缓解紧张和焦虑,使你更容易入睡。
4. 避免饮用含有咖啡因的饮料:咖啡因是一种刺激性物质,会影响你的睡眠质量。尽量避免在睡前饮用含有咖啡因的饮料,例如咖啡,茶和可乐。
5. 避免在床上做与睡眠无关的事情:在床上做些与睡眠无关的事情,例如看电影,玩游戏或工作等,可能会干扰你的睡眠。
6. 尝试呼吸技巧:深呼吸是一种放松技巧,可以帮助你缓解紧张和焦虑,使你更容易入睡。试着慢慢吸气,保持几秒钟,然后缓慢呼气。
如果这些方法无法帮助你入睡,你可以考虑咨询医生或睡眠专家,寻求进一步的建议。
模型的实现仍然处在变动中。如果希望固定使用的模型实现以保证兼容性,可以在 from_pretrained 的调用中增加 revision="v1.1.0" 参数。v1.1.0 是当前最新的版本号,完整的版本列表参见 Change Log。
从本地加载模型
以上代码会由 transformers 自动下载模型实现和参数。完整的模型实现可以在 Hugging Face Hub。如果你的网络环境较差,下载模型参数可能会花费较长时间甚至失败。此时可以先将模型下载到本地,然后从本地加载。
从 Hugging Face Hub 下载模型需要先安装Git LFS,然后运行
git clone https://huggingface.co/THUDM/chatglm-6b
如果你从 Hugging Face Hub 上下载 checkpoint 的速度较慢,可以只下载模型实现
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/THUDM/chatglm-6b
然后从这里手动下载模型参数文件,并将下载的文件替换到本地的 chatglm-6b 目录下。
将模型下载到本地之后,将以上代码中的 THUDM/chatglm-6b 替换为你本地的 chatglm-6b 文件夹的路径,即可从本地加载模型。
Optional 模型的实现仍然处在变动中。如果希望固定使用的模型实现以保证兼容性,可以执行
git checkout v1.1.0
Demo & API
我们提供了一个基于 Gradio 的网页版 Demo 和一个命令行 Demo。使用时首先需要下载本仓库:
git clone https://github.com/THUDM/ChatGLM-6B
cd ChatGLM-6B
首先安装 Gradio:pip install gradio,然后运行仓库中的 web_demo.py:
python web_demo.py
程序会运行一个 Web Server,并输出地址。在浏览器中打开输出的地址即可使用。最新版 Demo 实现了打字机效果,速度体验大大提升。注意,由于国内 Gradio 的网络访问较为缓慢,启用 demo.queue().launch(share=True, inbrowser=True) 时所有网络会经过 Gradio 服务器转发,导致打字机体验大幅下降,现在默认启动方式已经改为 share=False,如有需要公网访问的需求,可以重新修改为 share=True 启动。
感谢 @AdamBear 实现了基于 Streamlit 的网页版 Demo,运行方式见
命令行 Demo
运行仓库中 cli_demo.py:
python cli_demo.py
程序会在命令行中进行交互式的对话,在命令行中输入指示并回车即可生成回复,输入 clear 可以清空对话历史,输入 stop 终止程序。
API部署
首先需要安装额外的依赖 pip install fastapi uvicorn,然后运行仓库中的 api.py:
python api.py
默认部署在本地的 8000 端口,通过 POST 方法进行调用
curl -X POST "http://127.0.0.1:8000" \
-H 'Content-Type: application/json' \
-d '{"prompt": "你好", "history": []}'
得到的返回值为
{
"response":"你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。",
"history":[["你好","你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。"]],
"status":200,
"time":"2023-03-23 21:38:40"
}
低成本部署
模型量化
默认情况下,模型以 FP16 精度加载,运行上述代码需要大概 13GB 显存。如果你的 GPU 显存有限,可以尝试以量化方式加载模型,使用方法如下:
# 按需修改,目前只支持 4/8 bit 量化
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).quantize(8).half().cuda()
进行 2 至 3 轮对话后,8-bit 量化下 GPU 显存占用约为 10GB,4-bit 量化下仅需 6GB 占用。随着对话轮数的增多,对应消耗显存也随之增长,由于采用了相对位置编码,理论上 ChatGLM-6B 支持无限长的 context-length,但总长度超过 2048(训练长度)后性能会逐渐下降。
模型量化会带来一定的性能损失,经过测试,ChatGLM-6B 在 4-bit 量化下仍然能够进行自然流畅的生成。使用 GPT-Q 等量化方案可以进一步压缩量化精度/提升相同量化精度下的模型性能,欢迎大家提出对应的 Pull Request。
量化过程需要在内存中首先加载 FP16 格式的模型,消耗大概 13GB 的内存。如果你的内存不足的话,可以直接加载量化后的模型,INT4 量化后的模型仅需大概 5.2GB 的内存:
# INT8 量化的模型将"THUDM/chatglm-6b-int4"改为"THUDM/chatglm-6b-int8"
model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4", trust_remote_code=True).half().cuda()
量化模型的参数文件也可以从这里手动下载。
CPU 部署
如果你没有 GPU 硬件的话,也可以在 CPU 上进行推理,但是推理速度会更慢。使用方法如下(需要大概 32GB 内存)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).float()
如果你的内存不足,可以直接加载量化后的模型:
# INT8 量化的模型将"THUDM/chatglm-6b-int4"改为"THUDM/chatglm-6b-int8"
model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4",trust_remote_code=True).float()
如果遇到了报错 Could not find module 'nvcuda.dll' 或者 RuntimeError: Unknown platform: darwin (MacOS) ,请从本地加载模型
Mac 部署
对于搭载了 Apple Silicon 或者 AMD GPU 的Mac,可以使用 MPS 后端来在 GPU 上运行 ChatGLM-6B。需要参考 Apple 的 官方说明 安装 PyTorch-Nightly(正确的版本号应该是2.1.0.dev2023xxxx,而不是2.0.0)。
目前在 MacOS 上只支持从本地加载模型。将代码中的模型加载改为从本地加载,并使用 mps 后端:
model = AutoModel.from_pretrained("your local path", trust_remote_code=True).half().to('mps')
加载半精度的 ChatGLM-6B 模型需要大概 13GB 内存。内存较小的机器(比如 16GB 内存的 MacBook Pro),在空余内存不足的情况下会使用硬盘上的虚拟内存,导致推理速度严重变慢。此时可以使用量化后的模型如 chatglm-6b-int4。因为 GPU 上量化的 kernel 是使用 CUDA 编写的,因此无法在 MacOS 上使用,只能使用 CPU 进行推理。
# INT8 量化的模型将"THUDM/chatglm-6b-int4"改为"THUDM/chatglm-6b-int8"
model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4",trust_remote_code=True).float()
为了充分使用 CPU 并行,还需要单独安装 OpenMP。
多卡部署
如果你有多张 GPU,但是每张 GPU 的显存大小都不足以容纳完整的模型,那么可以将模型切分在多张GPU上。首先安装 accelerate: pip install accelerate,然后通过如下方法加载模型:
from utils import load_model_on_gpus
model = load_model_on_gpus("THUDM/chatglm-6b", num_gpus=2)
即可将模型部署到两张 GPU 上进行推理。你可以将 num_gpus 改为你希望使用的 GPU 数。默认是均匀切分的,你也可以传入 device_map 参数来自己指定。
高效参数微调
基于 P-tuning v2 的高效参数微调。具体使用方法详见 ptuning/README.md。
ChatGLM-6B 示例
以下是一些使用 web_demo.py 得到的示例截图。更多 ChatGLM-6B 的可能,等待你来探索发现!
局限性
由于 ChatGLM-6B 的小规模,其能力仍然有许多局限性。以下是我们目前发现的一些问题:
-
模型容量较小:6B 的小容量,决定了其相对较弱的模型记忆和语言能力。在面对许多事实性知识任务时,ChatGLM-6B 可能会生成不正确的信息;它也不擅长逻辑类问题(如数学、编程)的解答。
点击查看例子
-
产生有害说明或有偏见的内容:ChatGLM-6B 只是一个初步与人类意图对齐的语言模型,可能会生成有害、有偏见的内容。(内容可能具有冒犯性,此处不展示)
-
英文能力不足:ChatGLM-6B 训练时使用的指示/回答大部分都是中文的,仅有极小一部分英文内容。因此,如果输入英文指示,回复的质量远不如中文,甚至与中文指示下的内容矛盾,并且出现中英夹杂的情况。
-
易被误导,对话能力较弱:ChatGLM-6B 对话能力还比较弱,而且 “自我认知” 存在问题,并很容易被误导并产生错误的言论。例如当前版本的模型在被误导的情况下,会在自我认知上发生偏差。

