AI全栈利器开源Ollama+Qwen2.5-Code跑bolt.new,一键生成网站
最近,AI 编程工具非常火爆,从 Cursor、V0、Bolt.new 再到最近的 Windsurf。
本篇我们先来聊聊开源方案-Bolt.new,产品上线四周,收入就高达400万美元。
无奈该网站国内访问速度受限,且免费 Token 额度有限。
怎么在本地运行,让更多人用上,加速AI落地,是猴哥的使命。
今日分享,带大家用本地 Ollama 部署的大模型,驱动 bolt.new,实现 AI 编程的 Token 自由。

1. Bolt.new 简介
Bolt.new 是基于SaaS的AI编码平台,底层是由 LLM 驱动的智能体,结合WebContainers 技术,在浏览器内即可实现编码和运行,其优势有:
-
支持前后端同时开发; -
项目文件夹结构可视化; -
环境自托管,自动安装依赖(如 Vite、Next.js 等); -
运行 Node.js 服务器,从部署到生产
Bolt.new的目标是,让更多人都能完成 web应用开发,即便是编程小白,也能通过简单的自然语言实现创意。
官方已将项目开源:https://github.com/stackblitz/bolt.new
不过,官方开源的 bolt.new 支持模型有限,国内很多小伙伴都无法调用海外的 LLM API。
社区有大神二开了 bolt.new-any-llm,可支持本地 Ollama 模型,下面带大家实操一番。
2. Qwen2.5-Code 本地部署
前段时间,阿里开源了 Qwen2.5-Coder 系列模型,其中 32B 模型在十余项基准评测中均取得开源最佳成绩。
无愧全球最强开源代码模型,在多项关键能力上甚至超越 GPT-4o。
Ollama 模型仓库也已上线 qwen2.5-coder:
Ollama 是一款小白友好的大模型部署工具,不了解的小伙伴可回看教程:本地部署大模型?Ollama 部署和实战,看这篇就够了
2.1 模型下载
关于下载多大的模型,可根据自己的显存进行选择,32B 模型至少确保 24G 显存。
下面我们以 7b 模型进行演示:
ollama pull qwen2.5-coder
2.2 模型修改
由于 Ollama 的默认最大输出为 4096 个token,对于代码生成任务而言,显然是不够的。
为此,需要修改模型参数,增加上下文 Token 数量。
首先,新建 Modelfile 文件,然后填入:
FROM qwen2.5-coder
PARAMETER num_ctx 32768
然后,开始模型转换:
ollama create -f Modelfile qwen2.5-coder-extra-ctx
转换成功后,再次查看模型列表:
2.3 模型运行
最后,在服务端检查一下,看模型能否被成功调用:
def test_ollama():
url = 'http://localhost:3002/api/chat'
data = {
"model": "qwen2.5-coder-extra-ctx",
"messages": [
{ "role": "user", "content": '你好'}
],
"stream": False
}
response = requests.post(url, json=data)
if response.status_code == 200:
text = response.json()['message']['content']
print(text)
else:
print(f'{response.status_code},失败')
如果没什么问题,就可以在 bolt.new 中调用了。
3. Bolt.new 本地运行
3.1 本地部署
step1: 下载支持本地模型的 bolt.new-any-llm:
git clone https://github.com/coleam00/bolt.new-any-llm
step2: 复制一份环境变量:
cp .env.example .env
step3: 修改环境变量,将OLLAMA_API_BASE_URL替换成自己的:
# You only need this environment variable set if you want to use oLLAMA models
# EXAMPLE http://localhost:11434
OLLAMA_API_BASE_URL=http://localhost:3002
step4: 安装依赖(需本地已安装好 node)
sudo npm install -g pnpm # pnpm需要全局安装
pnpm install
step5: 一键运行
pnpm run dev
看到如下输出,说明启动成功:
➜ Local: http://localhost:5173/
➜ Network: use --host to expose
➜ press h + enter to show help
3.2 效果展示
浏览器中打开http://localhost:5173/,选择 Ollama 类型模型:
注意:首次加载,如果没拉取到 Ollama 中的模型,多刷新几次看看看。
来实测一番~
写一个网页端贪吃蛇游戏
左侧是流程执行区域,右侧是代码编辑区域,下方是终端区域。写代码、安装依赖、终端命令,全部由 AI 帮你搞定!

如果遇到报错,直接把报错丢给它,再次执行,如果没什么问题,右侧Preview页面就可以成功打开。
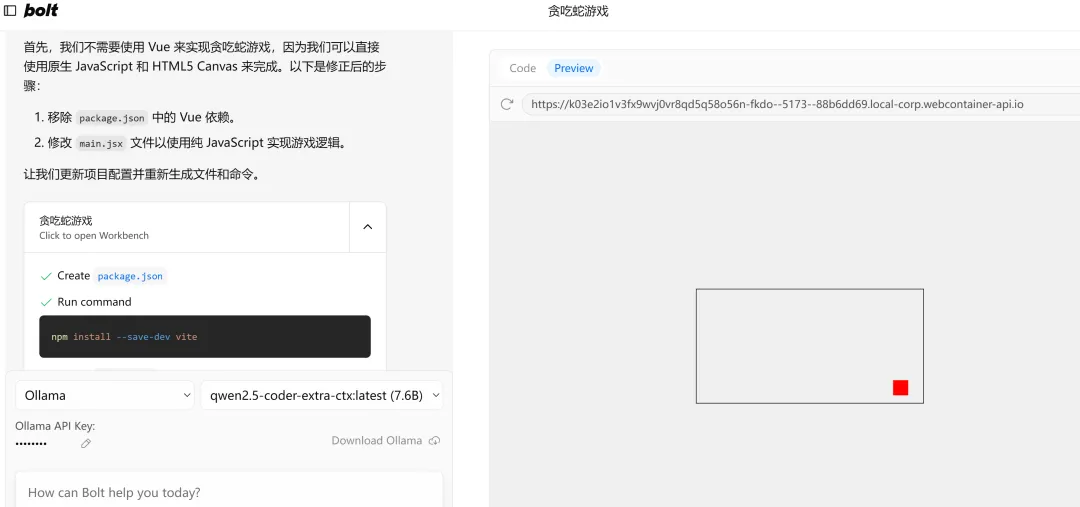
注:由于示例中用的 7b 小模型,有需要的朋友可以尝试用 32b 模型,效果会有显著提升。
写在最后
本文带大家在本地部署了 qwen2.5-code 模型,并成功驱动 AI 编程工具 bolt.new。
用它来开发前端项目还是相当给力的,当然,要想用好它,懂点基本的前后端概念,会事半功倍。