
问答社区
Deepseek发布1.3B小模型惊人的多模态视觉和语言元素理解和图片生成能力
本文介绍了Janus,一种用于统一多模态理解和生成的自回归框架。传统研究常依赖于单一的视觉编码器来处理这两项任务。然而,由于多模态理解和生成所需的信息粒度不同,这种方法可能导致性能不佳,尤其是在多模态理解部分。Janus通过解耦视觉编码路径,同时利用统一的Transformer架构进行处理,缓解了视觉编码器在理解和生成中的角色冲突,增强了框架的灵活性。实验表明,Janus超越了先前的统一模型,并匹敌或超过了任务特定模型的性能。其简单性、高灵活性和有效性使其成为下一代统一多模态模型的有力候选者。
觉生成
视觉生成是一个快速发展的领域,结合了自然语言处理的概念和Transformer架构的进步。自回归模型受到视觉Token(代码簿ID)的影响,这些模型将视觉数据进行标记,并采用类似于GPT风格的预测方法。此外,掩码预测模型借鉴了BERT风格的掩码方法,通过预测视觉输入中遮住的部分来提高合成效率,并已被适用于视频生成。与此同时,连续扩散模型在视觉生成中展现了令人印象深刻的能力,补充了离散方法。
多模态理解
多模态大语言模型(MLLMs)集成了文本和图像。通过利用预训练的LLMs,MLLMs显示了理解和处理多模态信息的强大能力。最近的进展探索了利用预训练的扩散模型来促进图像生成。这些方法属于工具利用的范畴,扩散模型根据MLLM输出的条件生成图像,而MLLM本身不具备直接视觉生成的能力。此外,系统的生成能力通常受到外部扩散模型的限制,使其性能不如直接使用扩散模型。
统一多模态理解和生成
统一的多模态理解和生成模型被认为在不同模态间促进无缝推理和生成方面非常强大。传统方法通常为理解和生成这两项任务使用单一的视觉表示,无论是基于自回归模型还是扩散模型。不同于此,Janus能够显式解耦理解和生成的视觉表示,认识到不同任务可能需要不同层次的信息。

Janus的架构如上图所示。对于纯文本理解、多模态理解和视觉生成,应用独立的编码方法将原始输入转换为特征,然后通过统一的自回归Transformer处理。对于文本理解,使用LLM的内置标记器将文本转换为离散ID。对于多模态理解,使用SigLIP编码器从图像中提取高维语义特征。这些特征从2D网格平铺成1D序列,然后通过理解适配器映射到LLM的输入空间。在生成任务中,使用生成适配器将代码簿嵌入映射到LLM的输入空间。使用LLM内置的预测头进行文本预测,而视觉生成任务中的图像预测使用随机初始化的预测头。

阶段一:训练适配器和图像头
这一阶段的主要目标是在嵌入空间内创建视觉和语言元素之间的概念连接,使LLM能够理解图像中的实体并具备初步的视觉生成能力。在此阶段,视觉编码器和LLM保持冻结,只有理解适配器、生成适配器和图像头中的可训练参数可以更新。
阶段二:统一预训练
通过多模态语料进行统一预训练,使Janus能够学习多模态理解和生成。我们解冻LLM,并利用所有类型的训练数据,包括纯文本数据、多模态理解数据和视觉生成数据。首先进行简单的视觉生成训练,随后使用一般的文本到图像数据提升模型的开放域视觉生成能力。
阶段三:监督微调
在这一阶段,通过指令微调数据对预训练模型进行微调,以增强其跟随指令和对话的能力。使用纯文本对话数据、多模态理解数据和视觉生成数据的混合,以确保其在多种场景下的多样性。
训练目标
在文本理解和多模态理解任务中,计算整个序列的损失。在视觉生成任务中,只计算图像序列的损失。设计简洁,不对不同任务分配不同的损失权重。
推理
在推理过程中,模型采用下一个Token预测方法。对于纯文本理解和多模态理解,按照标准做法从预测分布中依次抽样Token。对于图像生成,利用无分类器指导,具体为每个Token计算Logit,其中无条件Logit用于指导。
可能的扩展
Janus的设计特色在于理解和生成的解耦编码器,简单且易于扩展。
多模态理解
可以选择更强的视觉编码器,如EVA-CLIP或InternViT,而无需担心编码器是否能处理视觉生成任务。还可以使用动态高分辨率技术处理高分辨率图像,使得模型能够扩展到任意分辨率。
视觉生成
可以选择更精细的编码器以保留更多图像细节,并采用专为视觉生成设计的损失函数。结合使用自回归和并行方法,减少生成过程中的累计错误。
支持额外模态
Janus的架构便于额外编码器的集成,适配如3D点云、触觉和EEG等各种模态,使其有潜力成为更强大的多模态通用模型。
实验实现细节
在实验中使用DeepSeek-LLM作为基础语言模型,最大支持序列长度为4096。理解任务的视觉编码器选择SigLIP-Large-Patch16-384。训练过程使用HAI-LLM框架,持续7天。
数据设置
- 阶段一使用来自ShareGPT4V的图像文本配对说明。
- 阶段二的数据包括文本数据、图文数据和图像说明数据等。
评估设置
- 多模态理解:在知名图像语言基准上进行评估,包括VQAv2等
- 视觉生成:使用MSCOCO-30K、MJHQ-30K和GenEval基准进行评估
与最新技术对比
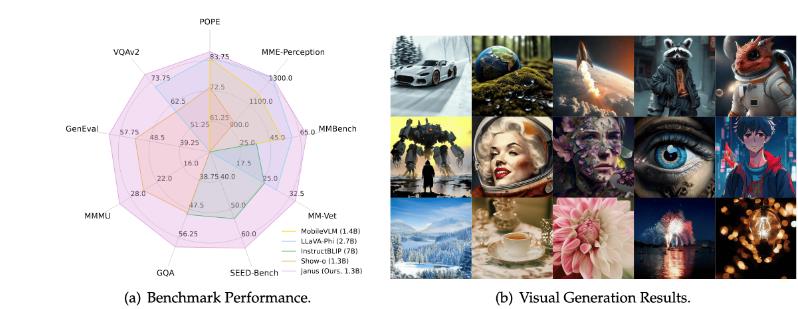
- 多模态理解:Janus在类似规模的模型中取得最佳结果。
- 视觉生成:Janus在GenEval中表现优异。
消融研究
设计消融实验验证Janus设计的有效性。结果显示视觉编码的解耦对于兼顾多模态理解和生成至关重要。
用户示例解读
Janus提供的示例显示了对用户提示的出色一致性。


定性结果
视觉生成可视化
如下图所示,对比了Janus与其他模型的视觉生成效果。结果显示,Janus在视觉生成中体现了优越的指令跟随能力,能够准确捕捉用户提示的大部分细节。
多模态理解在MEME图像上的结果
如下图展示了Janus在多模态理解方面的能力,与其他模型进行比较。Janus能够准确解释图片中的文字说明和情绪传达,而其他模型在准确识别图像文字上存在困难。这些例子突显了解耦视觉编码器相较于共享编码器在细粒度多模态理解能力上的显著提升。
结论
本文介绍了Janus,一个简单、统一且可扩展的多模态理解与生成模型。Janus的核心理念是为多模态理解和生成解耦视觉编码,从而减轻视觉编码器在理解和生成中需求差异引发的冲突。大量实验表明,Janus具有领先性能。其在理解和生成中的提升潜力,以及易于扩展以整合更多输入模态,使其成为下一代多模态通用模型的灵感。
附录
语义标记器的架构和训练
语义标记器分为两个阶段进行训练。第一阶段在ImageNet-1k数据集上训练,第二阶段在5000万图像上进行微调。这些图像来自Janus预训练过程中的视觉生成数据。
语义标记器与LLM的集成
语义标记器和LLM的集成如图所示,通过连续特征进行图像的处理。
额外的定性结果
更多文本到图像的生成结果展示了Janus在各种上下文输入中的卓越能力。

Deepseek-ai-Janus镜像仓库代码:https://github.com/deepseek-ai/Janus.git

