
问答社区
【面壁小钢炮 MiniCPM 3.0】强势超越 GPT-3.5,解锁无限长文本,推理实战全攻略
二、MiniCPM 3.0 的技术特点
-
MiniCPM 3.0 拥有 40 亿参数,虽然在大模型中参数规模不算庞大,但却能在性能上表现出色。 - 经过优化后,量化后仅需 2.2G 内存,这使得它能够在资源受限的端侧设备上运行,如手机、iPad 等移动设备。在 iPad 端侧推理能达到 18 - 20 tokens/s 的速度,满足实时交互的需求。
2. 强大的长文本处理能力
-
支持高达 32k 的上下文长度,能够轻松处理非常庞大的文本数据集。 -
采用创新的 LLMxMapReduce 长文本分帧处理技术,将长文本分割成多个子任务,然后递归地进行处理。即使在端侧有限的算力条件下,也能高效处理超长文本,并且在文本不断加长的情况下,仍能保持稳定性能,减少长文本随加长而掉分的情况。
3. 函数调用功能
-
用户可以以自然语言形式向 AI 发出指令,模型会将这些模糊的输入转化为具体的命令去操作外部工具或系统。 -
极大地拓展了模型的应用边界,使人机交互更加自然和方便。
4. 检索增强生成(RAG)
-
结合了信息检索技术和生成式 AI 的优势,在生成内容时可以利用已有的知识库。 -
一口气上线了 RAG 三件套,包括检索模型、重排序模型和面向 RAG 场景的 LoRA 插件,提高了输出的质量和准确性,减少大模型的幻觉问题。
5. 代码解释器
三、MiniCPM 3.0 的性能表现
1. 在中文能力基准测试中的卓越表现
- 在 CMMLU、CEval 等考究中文能力的基准测试中,MiniCPM 3.0 轻松碾压 Phi - 3.5、以及 GPT - 3.5 等模型。
- 即便是对上 8b、9b 等国内优秀的大模型,MiniCPM 3.0 的表现同样出众。
2. 出色的数学能力
- 在 Math Bench 上的效果超越 GPT - 3.5 - Turbo 以及多个 7b - 9b 模型。
- 在具有挑战性的 Live Code Bench 上,效果超越 Llama 3.1 - 8b - Instruct。
在英文指令遵循 IfEval、中文指令遵循 Follow Bench - Zh 方面效果超越 GLM - 4 - 9b - Chat、Qwen 2 - 7b - Instruct 等模型。

四、MiniCPM 3.0 的应用场景
-
作为智能客服的核心技术,MiniCPM 3.0 能够为用户提供快速、准确的解答。 -
提高客户满意度,同时降低企业的运营成本。
-
帮助用户进行文章写作、新闻报道、广告文案等文本创作。 -
为内容创作者提供高效的工具,提高创作效率和质量。
-
可以作为一种高效的语言翻译工具,为用户提供准确、流畅的翻译服务。 -
支持多种语言之间的翻译,满足全球化时代的语言需求。
-
在电商、新闻、视频等领域提供个性化的推荐服务。 -
提高用户的满意度和忠诚度,同时增加企业的销售额和利润。
五、MiniCPM 3.0模型下载
我们可以采用 modelscope 的 snapshot_download 来进行 MiniCPM 3.0 模型的下载。在此之前,需要提前安装 modelscope,可通过执行 “pip install modelscope” 命令来完成。在下载过程中,第一个参数需设置为 modelscope 上的模型路径,而 cache_dir 则用于指定模型的本地存放地址。这样的下载方式确保了模型能够准确、高效地存储在本地,为后续的推理操作做好准备。
#模型下载
from modelscope import snapshot_downloadsnapshot_download('OpenBMB/MiniCPM3-4B', cache_dir='/root/autodl-tmp', revision='master') 下载完成如下:
六、Transformers推理测试
Transformers 是由 Hugging Face 开发的开源库,可用于众多自然语言处理任务,其中包括语言模型推理。它提供了一系列预训练模型与工具,让开发者能够便捷地进行文本生成、语言翻译、问答系统等任务的开发及推理。该库具备简洁易用的接口,方便用户加载预训练模型,并进行推理和微调等操作。
1、安装依赖
pip install transformers
pip install datamodel-code-generator
pip install 'accelerate>=0.26.0'
2、推理示例from transformers import AutoModelForCausalLM, AutoTokenizerimport torchtorch.manual_seed(0) # 设置随机数种子,确保实验可重复性。path = '/root/autodl-tmp/OpenBMB/MiniCPM3-4B'# 从指定路径加载分词器tokenizer = AutoTokenizer.from_pretrained(path)# 从指定路径加载因果语言模型,设置数据类型为 bfloat16,将模型映射到 CUDA 设备,设置信任远程代码以便正确加载模型相关的代码和配置model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch.bfloat16, device_map='cuda', trust_remote_code=True)# 使用模型的聊天功能进行交互,传入分词器、问题文本、温度参数(用于控制生成的随机性)、top_p 参数(用于控制生成的多样性),返回响应内容和交互历史responds, history = model.chat(tokenizer, "请写一篇关于人工智能的文章,详细介绍人工智能的未来发展和隐患。", temperature=0.7, top_p=0.7)# 打印生成的响应内容print(responds)输出:

七、SGLang 推理测试
git clone https://github.com/sgl-project/sglang.gitcd sglangpip install --upgrade pippip install -e "python[all]"
pip install flashinfer -i https://flashinfer.ai/whl/cu121/torch2.4/python -m sglang.launch_server --model /root/autodl-tmp/OpenBMB/MiniCPM3-4B --trust-remote-code --port 30000 --chat-template chatml --disable-cuda-graph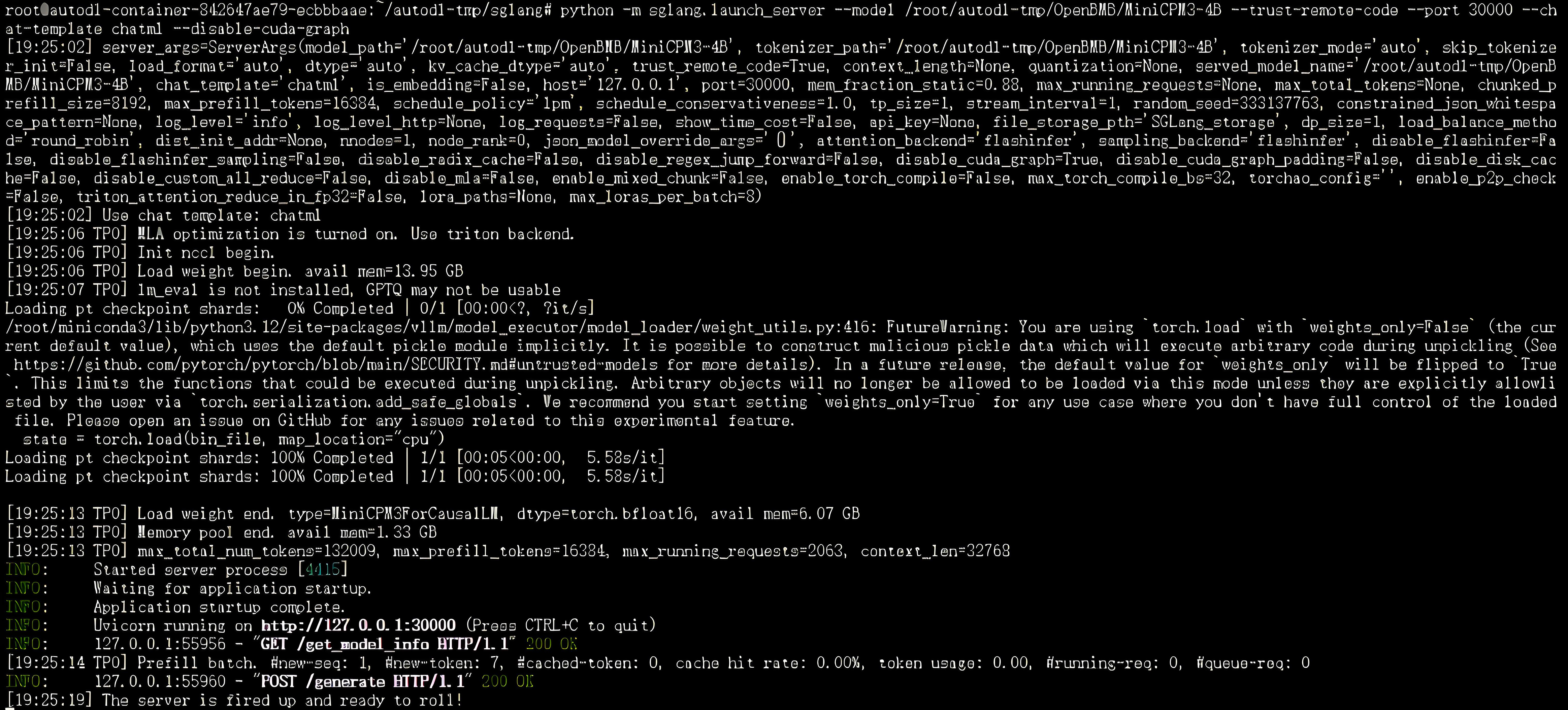
curl http://localhost:30000/generate \-H "Content-Type: application/json" \-d '{"text": "在很久以前,","sampling_params": {"max_new_tokens": 16,"temperature": 0}}'
输出响应:
{"text":"有一个小村庄,村庄里住着一群快乐的小动物。他们每天一起","meta_info":{"prompt_tokens":5,"completion_tokens":16,"completion_tokens_wo_jump_forward":16,"finish_reason":{"type":"length","length":16},"id":"3b12bec7d6bc4321b2c38c6a4acc1b53"},"index":0}
5、python代码调用服务
import openaiclient = openai.Client(base_url="http://127.0.0.1:30000/v1", api_key="EMPTY")# Text completionresponse = client.completions.create(model="default",prompt="The capital of France is",temperature=0,max_tokens=32,)print(response)print("--------------------------------------------------")# Chat completionresponse = client.chat.completions.create(model="default",messages=[{"role": "system", "content": "You are a helpful AI assistant"},{"role": "user", "content": "你叫什么名字?"},],temperature=0,max_tokens=64,)print(response.choices[0].message.content)
八、vLLM推理测试
pip install vllm==0.6.2vllm serve /root/autodl-tmp/OpenBMB/MiniCPM3-4B --dtype auto --api-key token-abc123 --trust-remote-code --max_model_len 2048 --gpu_memory_utilization 0.7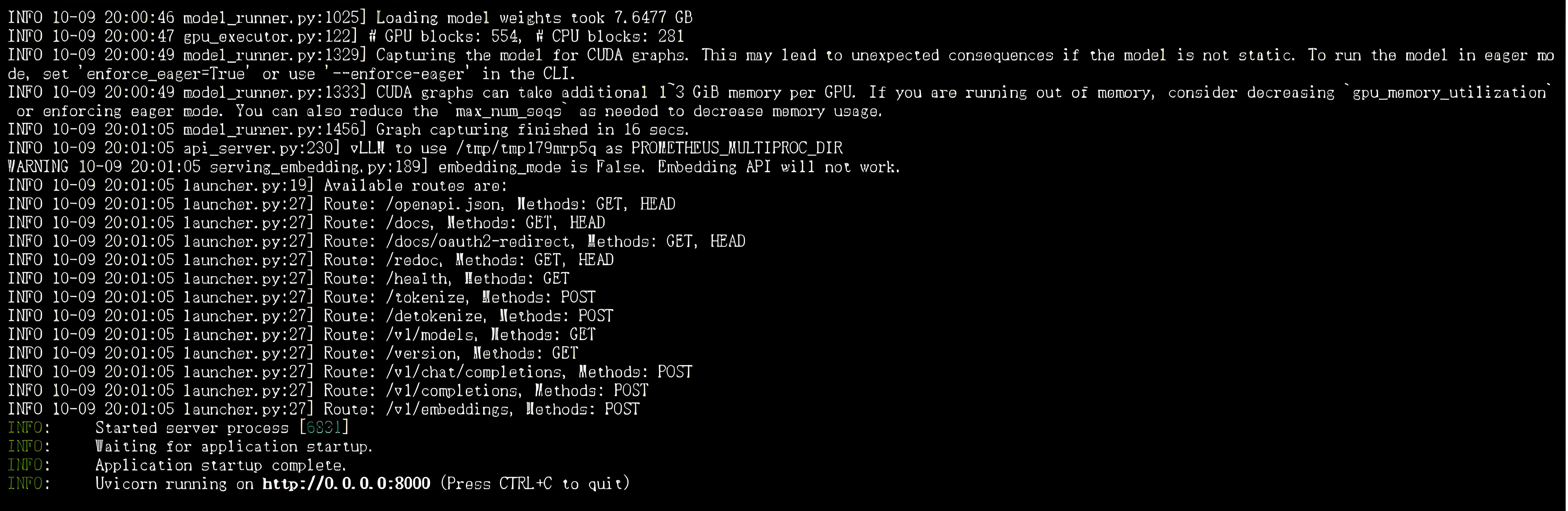
- --model /root/ld/ld_model_pretrained/minicpm3 #模型地址
- --served-model-name MiniCPM3-4B #模型的名字,可以自定义,在调用脚本中会用到
- --dtype auto # 设置的精度,比如bf16,fp16
- --api-key token-abc123 # 可以理解为你的密码,调用脚本中会用到
- --tensor-parallel-size 1 # 使用多少张卡,建议1,2,4,8
- --max_model_len 4096 # 模型的最长上下文,越长占用显存越多,必须设置
- --gpu_memory_utilization 0.9 # 使用多少显存来运行这个模型,1代表100%
- --trust-remote-code # 不要改,这里是是否使用远程代码
- --enforce_eager # 使用eager模式,这个模式下显存占用较少
3、服务调用
from openai import OpenAIclient = OpenAI(base_url="http://localhost:8000/v1",api_key="token-abc123",)completion = client.chat.completions.create(model="/root/autodl-tmp/OpenBMB/MiniCPM3-4B",messages=[{"role": "user", "content": "你好,很高兴见到你!"}])print(completion.choices[0].message)
ChatCompletionMessage(content='你好!很高兴见到你,人类朋友!非常高兴能与你交谈,希望我们的对话能够愉快而富有启发。请告诉我,你有什么问题或者想聊的话题,我在这里倾听并乐意帮助。', refusal=None, role='assistant', function_call=None, tool_calls=[])
九、Llamacpp推理测试
git clone https://github.com/ggerganov/llama.cpp.git2、编译llama.cpp
cd llama.cpp
make3、获取MiniCPM的gguf模型
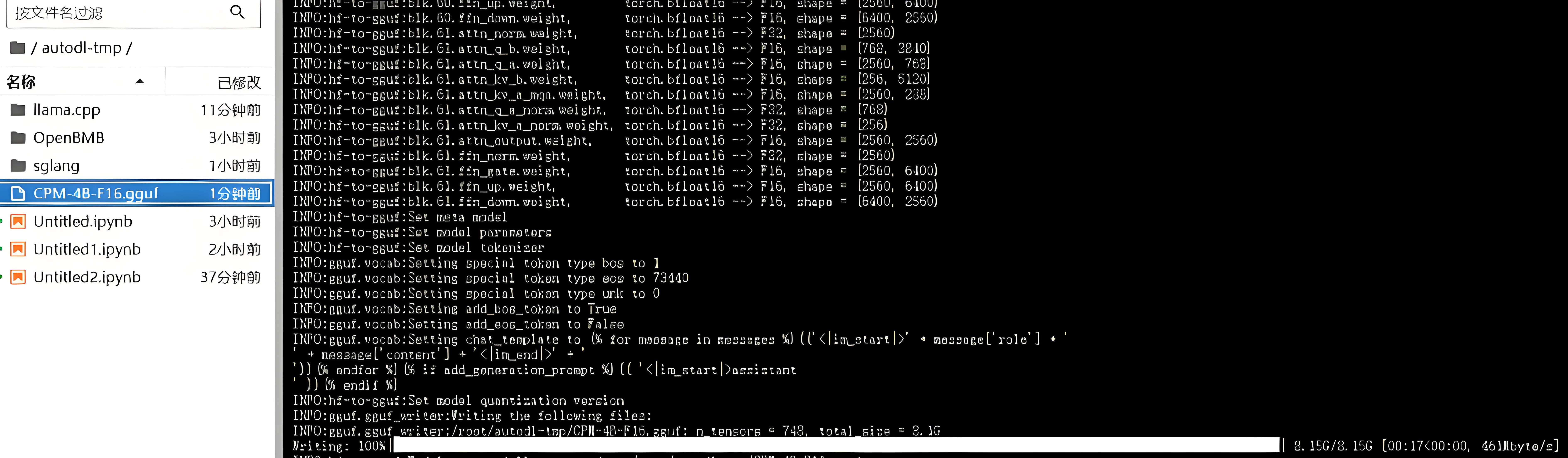
pip install -r requirements.txt#将pytorch模型转化为fp16的ggufpython convert_hf_to_gguf.py /root/autodl-tmp/OpenBMB/MiniCPM3-4B/ --outfile /root/autodl-tmp/CPM-4B-F16.gguf
./llama-cli -c 1024 -m /root/autodl-tmp/CPM-4B-F16.gguf -n 1024 --top-p 0.7 --temp 0.7 --prompt "<|im_start|>user\n请写一篇关于西安旅游的文章,详细介绍一下西安的旅游景点。<|im_end|>\n<|im_start|>assistant\n"推理如下:

5、启动api服务
./llama-server -m /root/autodl-tmp/CPM-4B-F16.gguf -c 2048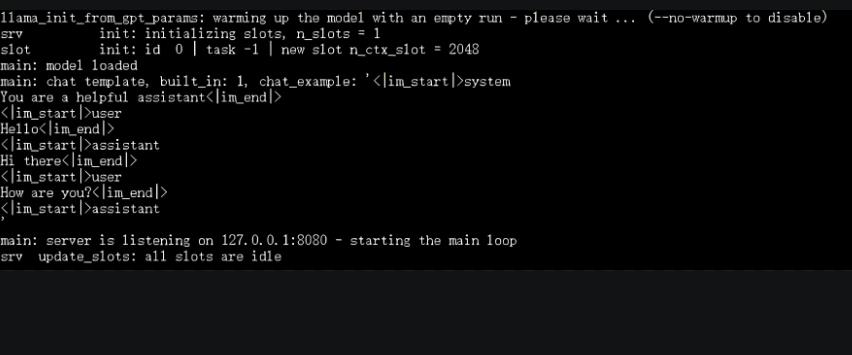
import requests
url = "http://localhost:8080/completion"headers = { "Content-Type": "application/json"}data = { "prompt": "MiniCPM3 是哪家公司发布的?", "n_predict": 128}
response = requests.post(url, json=data, headers=headers)
if response.status_code == 200: result = response.json() print(result["content"])else: print(f"Request failed with status code {response.status_code}: {response.text}")答:MiniCPM3 是由面壁智能公司发布的。结语

