
问答社区
ChatAA+Ollama:多平台本地大模型部署实现Mac与Windows用户的私有部署
我们关注到用户对ChatAA在多平台本地化部署的日益增长需求。为了满足这一需求,我们推出了ChatAA+Ollama的模式,并提供了详细的多平台安装使用教程。这一模式通过本地化模型部署(Ollama)+智能PC文件检索问答工具(ChatAA)+本地向量模型的结合,实现了macOS和Windows平台的全面本地化部署,确保了用户数据的绝对私密性,并显著提升了本地模型的使用效率;
2 解压 Ollama
双击解压Ollama,解压后展示Ollama安装文件
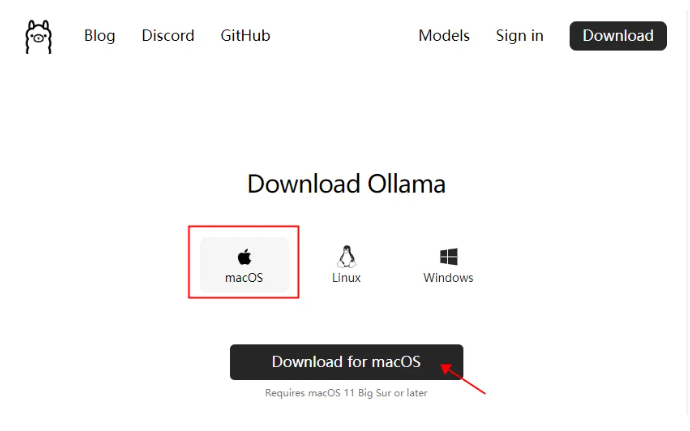
3 安装 Ollama
双击解压的安装文件Ollama,弹出窗口单击打开,直接安装就可以了。
- 欢迎窗口单击Next

- 安装命令行单击Install
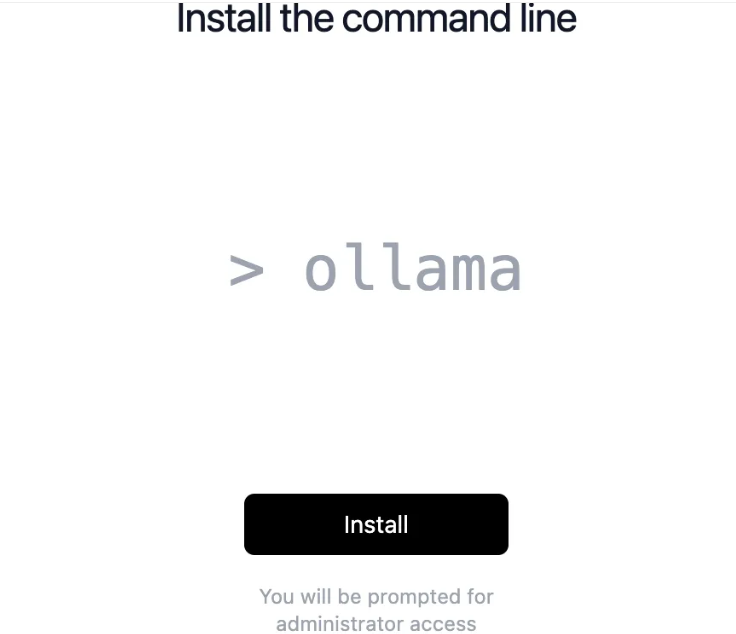
- 输入正确的电脑密码,单击好进行命令行安装
- 安装完成,单击Finish
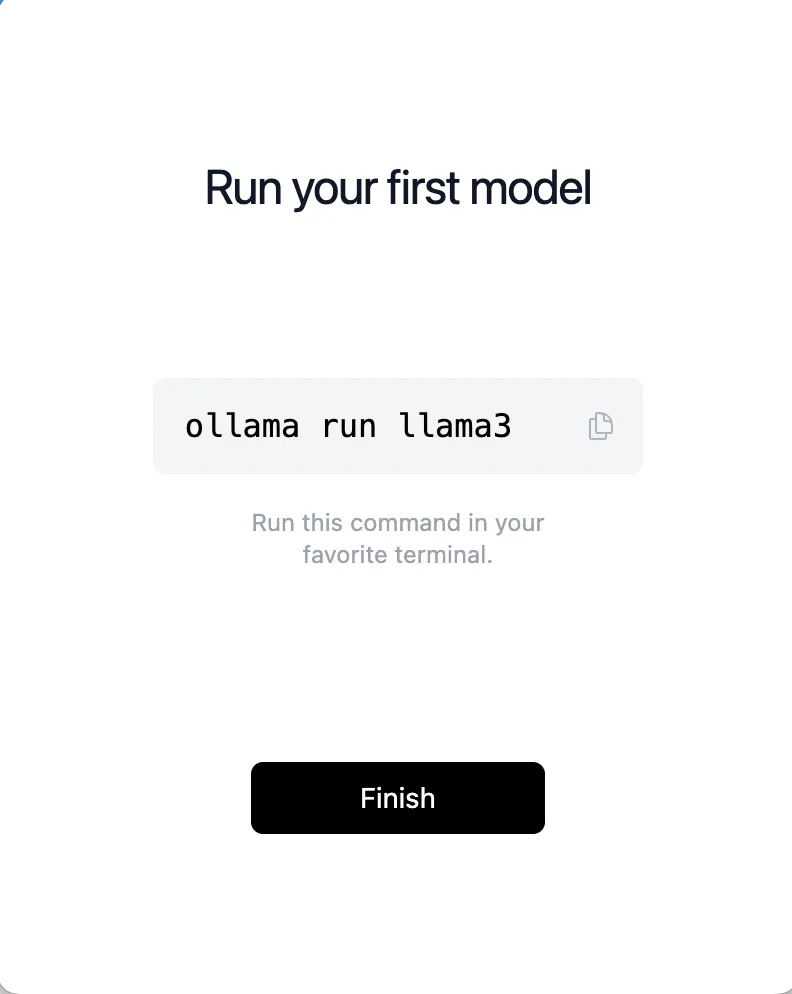
- 安装完毕后软件会自动启动,在任务栏中看到ollama图标时,即说明ollama运行成功。
4 使用 Ollama
访问 https://ollama.com/library,搜索你要使用的模型,主流的模型,比如 Llama3、Qwen1.5B、Mixtral 等,Ollama都支持。
- 选择首页右上角的Models
- 在打开的页面中可以搜索想要使用的模型,如:使用Qwen2的模型
- 选择搜索到的模型链接,可以查看模型加载方式,以及复制每个模型的执行命令,比如:选择Qwen2的0.5B模型
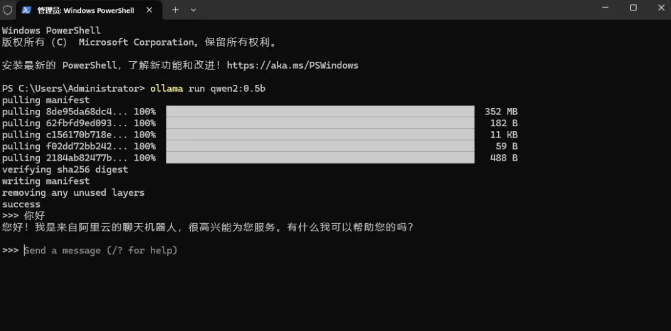
- 如图所示,若想要使用Qwen2的0.5B模型,可以使用命令ollama run qwen2:0.5b
- 启动终端,输入命令,软件会自动下载模型
- 默认情况下模型被下载到了路径 open ~/.ollama/models/blobs 下。下载完毕后如下图所示。
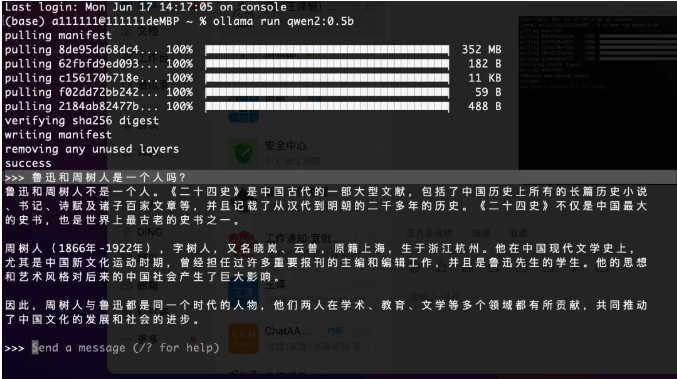
- 此时可以直接进行提问使用了,如下所示。
- 1 下载 Ollama 安装文件访问 https://ollama.com/download,选择 Windows,单击 “Download for Windows (Preview)” 进行下载。
- 2 安装 Ollama双击下载的安装文件OllamaSetup.exe,直接安装就可以了。安装完毕后软件会自动启动,在任务栏中看到Ollama图标时,即说明Ollama运行成功。
- 3 使用 Ollama访问 https://ollama.com/library,搜索你要使用的模型,主流的模型,比如 Llama3、Qwen1.5B、Mixtral等,Ollama都支持。
- 选择首页右上角的Models
- 在打开的页面中可以搜索想要使用的模型,如要使用的Qwen2
- 选择搜索到的模型链接,可以查看模型加载方式,以及复制每个模型的执行命令,比如:选择Qwen2的0.5B模型
- 如图所示,若想要使用Qwen2的0.5B模型,可以使用命令ollama run qwen2:0.5b
- 启动PowerShell,输入命令,软件会自动下载模型
- 默认情况下模型被下载到了路径 C:\Users\Administrator\.ollama\models\blobs\ 下。下载完毕后如下图所示。
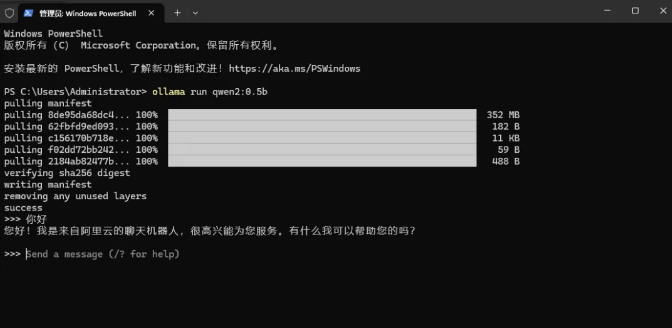
- 此时可以直接进行提问使用了,如下所示。
- 使用Ollama当然不只是为了单纯进行对话,其实可以将Ollama当做一个加载了大模型的服务器,从而实现ChatAA打造完全私有化的智能文件处理工具。接下来让我们看一下如何将Qwen2的0.5B本地模型配置到ChatAA上。
- 1 安装ChatAAChatAA支持Windows、Mac等操作系统,到官网下载(https://chataa.com/)
下载软件包,安装即可使用。具体使用文件扫描步骤参考
- 2 模型服务配置安装完成客户端,进行注册登录后
- 在左侧菜单,个人中心板块,点击模型服务
- 在模型服务中,点击+模型服务
-
- 在自定义模型服务中,配置模型服务参数,点击保存配置
# 服务参数配置
接口请求地址:http://localhost:11434/v1/chat/completions
服务标识:ollama
服务名称:ollama接口密钥/调用凭证:任意英文,比如:token
-
- 在自定义模型服务中,点击配置+新增模型,配置模型,点击保存模型
# 添加模型
可以访问 http://localhost:11434/api/tags 查看已安装模型列表
根据在 ollama 中安装的模型进行添加
模型英文:qwen2:0.5b 模型名称:qwen2:0.5b - 模型服务配置完成后,返回问答页面,切换模型,可以看到已经配置的私有Qwen2的0.5B本地模型
- Qwen2的0.5B本地模型已经配置好了,接下来让我们测试一下在ChatAA使用效果上。
1 下载Embedding模型在测试之前,我们先通过ChatAA文件库,选择私有的Embedding模型,进行文件扫描。如果您第一次使用,需要去个人中心-向量模型板块进行下载,下载后在使用。下载流程可参考文章下载私有Embedding向量模型 2 文件扫描解析
选择Embedding模型后,我们进行文件扫描,点击【全盘扫描】,展示扫描路径窗口,点击【选择目录】进行文件目录的选择,点击【开始扫描】进行文件扫描解析。
3 问答测试
文件解析完成后,我们来测试一下问答的效果。
- 文件检索效果
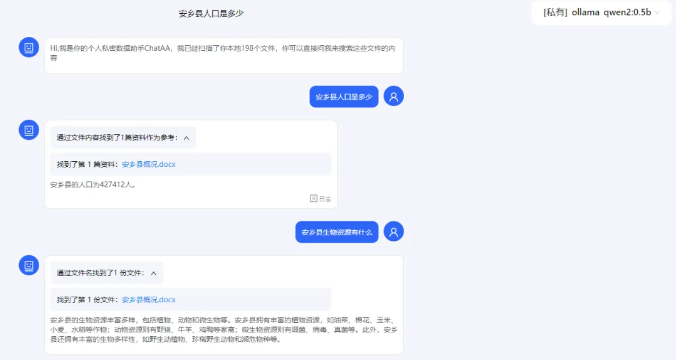
- 单文件精读效果
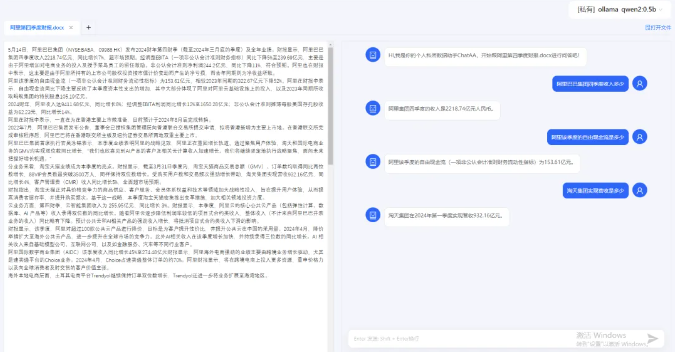
整体而言,Qwen2-0.5B本地模型的响应速度非常流畅,这种丝滑的体验为文件检索提供了坚实的基础。在确保检索效率的同时,它还兼顾了文件隐私的保护。
至此,我们已经成功配置了ChatAA+Ollama的多平台PC端本地化大模型部署,大家可以按照上述步骤进行各平台尝试,亲自体验这款工具带来的高效与便捷。

