
问答社区
川虎GPT🐯 – 本地开源AI对话客户端,速度优于ChatGPT,支持联网
 安装教程
安装教程
在 Hugging Face 上在线部署(最方便)
访问本项目的 Hugging Face页面,填入你的API-Key后,就可以直接和ChatGPT对话!无需注册无需代码,这是免费的。
Hugging Face的优点:免费,无需配置代理,部署容易(甚至不需要电脑)。
Hugging Face的缺点:不支持某些界面样式和效果,可能未使用最新的项目代码。
复制Space
使用技巧
💪 强力功能
- 川虎助理:类似 AutoGPT,全自动解决你的问题;
- 在线搜索:ChatGPT 的数据太旧?给 LLM 插上网络的翅膀;
- 知识库:让 ChatGPT 帮你量子速读!根据文件回答问题。
- 本地部署LLM:一键部署,获取属于你自己的大语言模型。
🤖 System Prompt
- 通过 System Prompt 设定前提条件,可以很有效地进行角色扮演;
- 川虎Chat 预设了Prompt模板,点击
加载Prompt模板,先选择 Prompt 模板集合,然后在下方选择想要的 Prompt。
💬 基础对话
- 如果回答不满意,可以使用
重新生成按钮再试一次,或者直接删除这轮对话; - 输入框支持换行,按 Shift + Enter即可;
- 在输入框按 ↑ ↓ 方向键,可以在发送记录中快速切换;
- 每次新建一个对话太麻烦,试试
单论对话功能; - 回答气泡旁边的小按钮,不仅能
一键复制,还能查看Markdown原文; - 指定回答语言,让 ChatGPT 固定以某种语言回答。
📜 对话历史
- 对话历史记录会被自动保存,不用担心问完之后找不到了;
- 多用户历史记录隔离,除了你都看不到;
- 重命名历史记录,方便日后查找;
- New! 魔法般自动命名历史记录,让 LLM 理解对话内容,帮你自动为历史记录命名!
- New! 搜索历史记录,支持正则表达式!
🖼️ 小而美的体验
- 自研 Small-and-Beautiful 主题,带给你小而美的体验;
- 自动亮暗色切换,给你从早到晚的舒适体验;
- 完美渲染 LaTeX / 表格 / 代码块,支持代码高亮;
- New! 非线性动画、毛玻璃效果,精致得不像 Gradio!
- New! 适配 Windows / macOS / Linux / iOS / Android,从图标到全面屏适配,给你最合适的体验!
- New! 支持以 PWA应用程序 安装,体验更加原生!
👨💻 极客功能
- New! 支持 Fine-tune(微调)gpt-3.5!
- 大量 LLM 参数可调;
- 支持更换 api-host;
- 支持自定义代理;
- 支持多 api-key 负载均衡。
⚒️ 部署相关
- 部署到服务器:在
config.json中设置"server_name": "0.0.0.0", "server_port": <你的端口号>,。 - 获取公共链接:在
config.json中设置"share": true,。注意程序必须在运行,才能通过公共链接访问。 - 在Hugging Face上使用:建议在右上角 复制Space 再使用,这样App反应可能会快一点。
快速上手
在终端执行以下命令:
git clone https://github.com/GaiZhenbiao/ChuanhuChatGPT.git
cd ChuanhuChatGPT
pip install -r requirements.txt
然后,在项目文件夹中复制一份 config_example.json,并将其重命名为 config.json,在其中填入 API-Key 等设置。
python ChuanhuChatbot.py
一个浏览器窗口将会自动打开,此时您将可以使用 川虎Chat 与ChatGPT或其他模型进行对话。
Note
具体详尽的安装教程和使用教程请查看本项目的wiki页面。
疑难杂症解决
在遇到各种问题查阅相关信息前,您可以先尝试 手动拉取本项目的最新更改1 并 更新依赖库2,然后重试。步骤为:
- 点击网页上的
Download ZIP按钮,下载最新代码并解压覆盖,或git pull https://github.com/GaiZhenbiao/ChuanhuChatGPT.git main -f
- 尝试再次安装依赖(可能本项目引入了新的依赖)
pip install -r requirements.txt
很多时候,这样就可以解决问题。
如果问题仍然存在,请查阅该页面:常见问题
-------------------------------------------------------------
该页面列出了几乎所有您可能遇到的各种问题,包括如何配置代理,以及遇到问题后您该采取的措施,请务必认真阅读。
您也可以将项目复制为私人空间里使用,这样App反应可能会快一点。
注册Hugging Face账户后,只需点击 Hugging Face Space 右上角的 Duplicate Space (复制空间),新建一个私人空间,然后就直接可以在私人空间中使用啦!放心,这也是免费的。
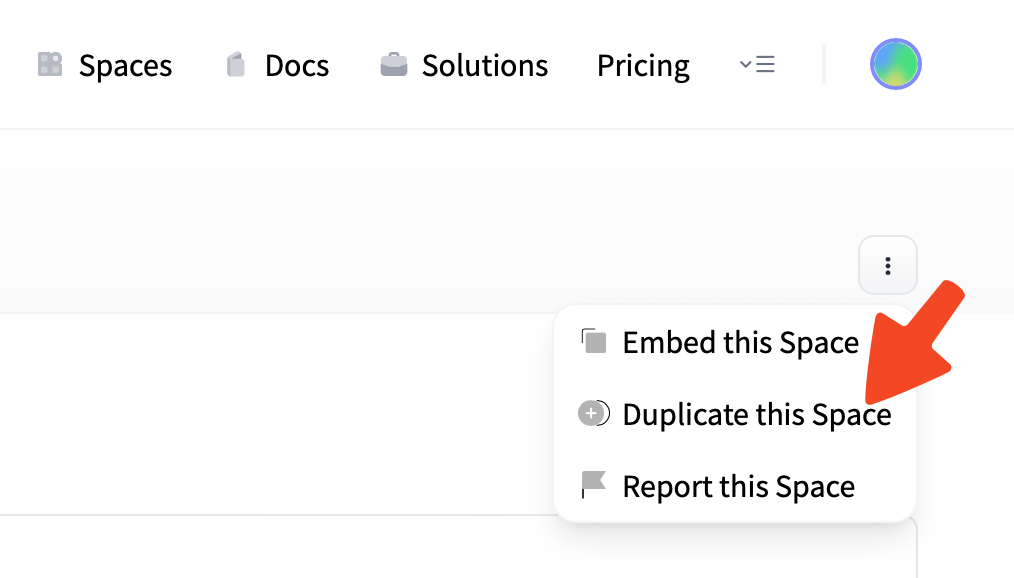
设置Space
复制Space时,你将会看到一条类似这样的提示:
This Space has 2 environment variables that might be needed to work correctly.
You can add those 2 secrets in your Space settings: HIDE_LOCAL_MODELS LANGUAGE你可以忽略这条提示,直接继续在你的私人空间中使用 川虎Chat。但事实上,如提示所写的那样,我们提供了填写环境变量来配置 川虎Chat 而无需编辑项目代码的方式。
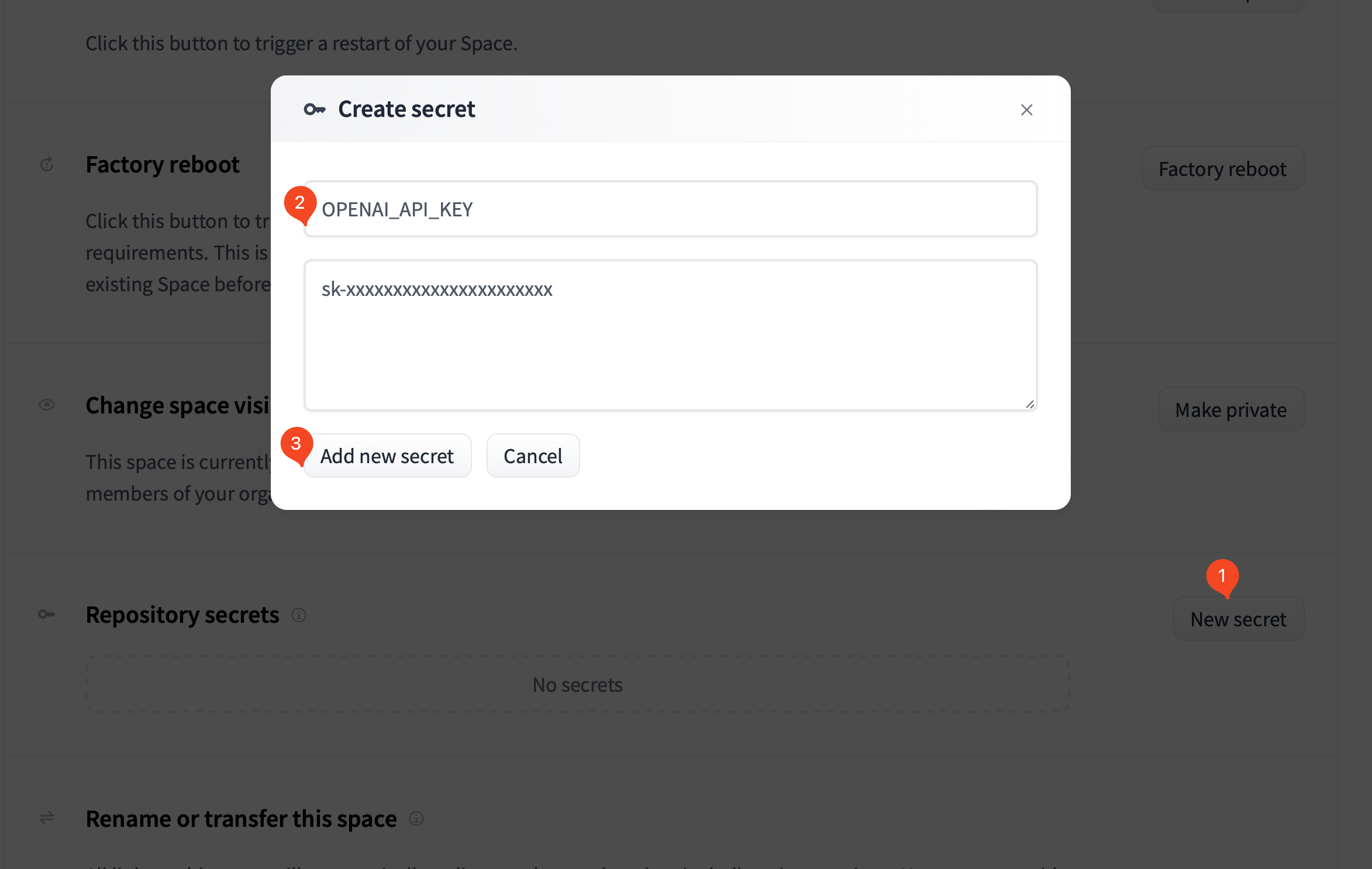
如果你已经复制了Space,你可以在Space的Settings页面找到 Repository secrets 这一栏,按下述指引新建并填写Secret:
OPENAI_API_KEY
用于设置你的OpenAI API-Key,这样无需每次手动输入API-Key。通过这种方式设置,你的Key不会被泄漏。OPENAI_API_BASE
用于设置 OpenAI API 的基础 URL,默认为api.openai.com。你可以将其设置为你自己修改部署的 API 地址。LANGUAGE
用于设置Space的语言,默认为英语。设置为zh_CN以显示中文,ja_JP以显示日文,en_US以显示英语,ko_KR以显示韩语。USAGE_LIMIT
用于设置 ChatGPT 显示额度与用量时的上限,单位为美元,默认为120。HIDE_LOCAL_MODELS
设置为true将会隐藏本地模型。这是因为本地模型会消耗非常多的资源,免费版的CPU Space可能不够用。然而,经过实际测试,ChatGLM-6B-int4可以在免费Space中跑起来,但速度非常慢(1-2秒一个字)。
更多项目配置Secret环境变量说明请参见配置 config.json.
本地部署
手动安装(适用于大部分用户)
- 下载本项目推荐使用 git 下载安装和更新本项目。
git clone https://github.com/GaiZhenbiao/ChuanhuChatGPT.git cd ChuanhuChatGPT什么是 git?怎么用 git 安装本项目?
或:从 Release zip 安装本项目
- 安装依赖请确保您已经安装Python,并且已经将pip加入环境变量。
- 为了避免产生太多依赖问题,建议使用的 Python 版本为 Python 3.10 或 Python 3.11。
- (可选)如果您有相关环境配置的经验,可以在这一步新建环境
conda create -n ChuanhuChat python=3.10 conda activate ChuanhuChat
在终端中输入下面的命令,然后回车。如果命令报错,请试试
pip3。pip install -r requirements.txt
如果下载慢,可以尝试为Pypi 配置豆瓣源,或者科学上网。
如果你还想使用本地运行大模型的功能,请再执行下面的命令:
pip install -r requirements_advanced.txt
- 填写项目配置您也可以略过本步骤,在第四步启动后直接在图形界面中填写您的API密钥。不过,如果您为自己或熟人部署 川虎Chat,我们建议您在这一步设定默认密钥、用户名密码以及更多设置。这样设置的密钥以及其他设置项可以在拉取项目更新之后保留。在项目文件夹中复制一份
config_example.json,并将其重命名为config.json,在其中填入 API-Key、用户名密码(可选)、API host(可选)、代理地址(可选)等设置。用户名密码支持多用户。示例:{ "openai_api_key": "sk-xxxxxxxxxxxxxxxxxxxxxxxxx", "users": [ ["用户1的用户名", "用户1的密码"], ["用户2的用户名", "用户2的密码"] ], }- 更多项目配置说明请查看 配置 config.json。
- 启动请使用下面的命令。取决于你的系统,你可能需要用
python或者python3命令。请确保你已经安装了Python。python ChuanhuChatbot.py
如果一切顺利,现在,你应该已经可以在浏览器地址栏中输入 http://localhost:7860 查看并使用 川虎Chat 了。
如果你在安装过程中碰到了问题,请先查看疑难杂症解决页面。
如果您已经有下载好的本地模型,请将它们放在models文件夹下面(文件名中需要包含llama/alpaca/chatglm等相应关键字),LoRA模型们则需要放在lora文件夹下。
关于本地运行大模型的功能,具体请参见:使用本地LLM模型。
自动安装(适用于使用 Windows 且没有信息技术相关概念的用户)
我们更推荐用户执行手动安装以实现更可控的环境配置。
需要注意,您可能还是需要在系统中安装 git 来保证全部功能的正常运行。
- 点击项目主页的右侧
Releases中的 最新版本号,查看最新的发行版信息, - 打开该发行版的 Assets,下载并解压其中的
ChuanhuChatGPT-<version>-git.zip, 解压完成后进入文件夹。 - 双击
run_Windows.bat,一个命令行窗口将会出现,并自动执行各种安装命令。稍等片刻,浏览器应该会自动打开http://localhost:7860供您使用 川虎Chat。- 您未来仍可通过双击
run_Windows.bat来启动 川虎Chat。
- 您未来仍可通过双击
如果您需要进一步配置 川虎Chat,请参见 配置 config.json。
使用 Docker 部署
如果觉得手动部署比较麻烦,我们提供了 Docker 镜像,可以直接运行。
Docker 镜像没有包含本地模型。若要使用本地模型,请参考安装本地模型所需的依赖。
- 创建文件夹创建存放 川虎Chat 配置和聊天记录的文件夹,例如
~/ChuanhuChatGPT。mkdir ~/ChuanhuChatGPT mkdir ~/ChuanhuChatGPT/history
- 拉取镜像并获取配置文件
docker run --rm tuchuanhuhuhu/chuanhuchatgpt:latest \ cat /app/config_example.json > ~/ChuanhuChatGPT/config.json
- 根据需求修改配置文件配置文件位于
~/ChuanhuChatGPT/config.json。请根据需求修改配置文件。配置文件的详细说明请参考 配置 config.json。 - 运行 Docker 容器
docker run -d --name ChuanhuChat \ -v ~/ChuanhuChatGPT/history:/app/history \ -v ~/ChuanhuChatGPT/config.json:/app/config.json \ -p 7860:7860 \ tuchuanhuhuhu/chuanhuchatgpt:latest
注:请根据配置文件实际情况修改
-v和-p参数。
查看容器运行状态
docker logs -f ChuanhuChat
修改配置文件
您可以改变 ~/ChuanhuChatGPT/config.json 中的配置,然后重启容器使配置生效。
docker restart ChuanhuChat
安装本地模型所需的依赖
本地模型所需的依赖占用空间较大(>5GB),考虑到镜像体积,镜像中默认没有安装。如果您需要使用本地模型,请先按上述教程运行容器。然后通过以下命令进入容器:
docker exec -it ChuanhuChat /bin/bash
然后进入 /app 目录,执行以下命令安装依赖:
pip install -r requirements_advanced.txt
关于本地运行大模型的功能,具体请参见:使用本地LLM模型。
自行构建镜像
您可通过修改项目根目录下的 Dockerfile 来自定义容器镜像。然后执行以下命令构建镜像:
docker build -t chuanhuchatgpt:latest .
远程部署
这一部分会教你如何在公网服务器部署本项目。
部署到公网服务器
在 config.json 中设置
{
...
"server_name": "0.0.0.0",
"server_port": <你的端口号>,
...
}
注意将<你的端口号>替换为实际的端口号。
配置 Nginx 反向代理
注意:配置反向代理不是必须的。如果需要使用域名,则需要配置 Nginx 反向代理。如果你碰到了网页右上角提示Connection Error的问题,也可以尝试通过配置Nginx反向代理解决。
又及:目前配置认证后,Nginx 必须配置 SSL,否则会出现 Cookie 不匹配问题。
添加独立配置文件:
server {
listen 80;
server_name /域名/; # 请填入你设定的域名
access_log off;
error_log off;
location / {
proxy_pass http://127.0.0.1:7860; # 注意端口号
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Upgrade $http_upgrade; # Websocket配置
proxy_set_header Connection $connection_upgrade; #Websocket配置
proxy_max_temp_file_size 0;
client_max_body_size 10m;
client_body_buffer_size 128k;
proxy_connect_timeout 90;
proxy_send_timeout 90;
proxy_read_timeout 90;
proxy_buffer_size 4k;
proxy_buffers 4 32k;
proxy_busy_buffers_size 64k;
proxy_temp_file_write_size 64k;
}
}
修改nginx.conf配置文件(通常在/etc/nginx/nginx.conf),向http部分添加如下配置: (这一步是为了配置websocket连接,如之前配置过可忽略)
map $http_upgrade $connection_upgrade {
default upgrade;
'' close;
}
为了同时配置域名访问和身份认证,需要配置SSL的证书,可以参考这篇博客一键配置。
全程使用 Docker 为本程序开启HTTPS
如果你的VPS 80端口与443端口没有被占用,且您倾向于使用 Docker,则可以考虑如下的方法,只需要将你的域名提前绑定到你的VPS 的IP即可。此方法由@iskoldt-X 提供。
首先,运行nginx-proxy
docker run --detach \
--name nginx-proxy \
--publish 80:80 \
--publish 443:443 \
--volume certs:/etc/nginx/certs \
--volume vhost:/etc/nginx/vhost.d \
--volume html:/usr/share/nginx/html \
--volume /var/run/docker.sock:/tmp/docker.sock:ro \
nginxproxy/nginx-proxy接着,运行acme-companion,这是用来自动申请TLS 证书的容器
docker run --detach \
--name nginx-proxy-acme \
--volumes-from nginx-proxy \
--volume /var/run/docker.sock:/var/run/docker.sock:ro \
--volume acme:/etc/acme.sh \
--env "DEFAULT_EMAIL=你的邮箱(用于申请TLS 证书)" \
nginxproxy/acme-companiondocker run -d --name ChuanhuChat \
-v ~/ChuanhuChatGPT/history:/app/history \
-v ~/ChuanhuChatGPT/config.json:/app/config.json \
-e VIRTUAL_HOST=你的域名 \
-e VIRTUAL_PORT=7860 \
-e LETSENCRYPT_HOST=你的域名 \
tuchuanhuhuhu/chuanhuchatgpt:latest如此即可为 川虎Chat 实现自动申请 TLS 证书并且开启 HTTPS。
使用教程
更新功能
使用 检查更新 按钮更新
你可以配置是否启用更新检查,如果启用,你可以在图形界面中点击 检查更新 按钮来检查更新。
{
...
"check_update": true, //是否启用检查更新
...
}
true: 启用检查更新(默认值)false: 禁用检查更新,同时UI中也不再显示检查更新按钮
如果存在发行版更新,你可以点击 更新 按钮来直接更新项目。更新将会通过 git 在后台自动执行,你可以在终端中检查更新状态。
- 如果你对项目有自定义修改,不用担心,我们会尝试帮你合并代码,你的更改不会被覆盖。
- 如果你的更改和最新的代码有冲突,我们会取消更新执行,并尝试将文件恢复到更新前的状态。你需要尝试手动更新,手动解决冲突。
- 如果更新出现了问题,请检查终端输出内容。
通过更新按钮获取的更新是发行版更新,不包含最新的代码(最新的代码可能存在bug,也可能解决了原先的bug)。如果你想要获取最新的主线代码,请参考手动更新。
自动更新
如果您使用Linux和macOS,则可以通过本项目提供的脚本检测仓库是否有更新,如果有,则拉取最新脚本、安装依赖、重启服务器。
对应您的系统,您只需要运行run_Linux.sh或者run_macOS.command即可。如果你还想始终保持最新版本,可以定时运行脚本。例如,在crontab中加入下面的内容:
*/20 * * * * /path/to/ChuanhuChatGPT/run_Linux.sh就可以每20分钟检查一次脚本更新。如果仓库主线(main)代码存在更新,则自动拉取最新主线代码并重启服务器。
手动更新
若您执行手动更新,您将获取我们最新的代码(可能存在bug,但也可能解决了原先的bug),而不是可能更稳定的发行版更新代码。
- 首先,获取最新的项目代码:
- (若您之前使用git安装):
- 在项目文件夹中进入终端(git bash)
注:如何在文件夹中进入终端或命令提示符(git bash)?
- 使用git拉取最新的代码:
git fetch https://github.com/GaiZhenbiao/ChuanhuChatGPT.git git pull https://github.com/GaiZhenbiao/ChuanhuChatGPT.git main --autostash
如果更新中止,可能是因为您对本地代码进行了修改,导致本地代码和最新代码有冲突。您需要手动解决冲突,具体操作请参考相关
git教程。
- 在项目文件夹中进入终端(git bash)
- (若您之前使用zip安装):
- 点击网页上的
Download ZIP下载最新代码并解压, - 备份您原项目文件夹中的
config.json, - 使用新下载的文件夹替换原项目文件夹,
- 将备份的
config.json放入新的项目文件夹中。
- 点击网页上的
- (若您之前使用git安装):
- 然后,再次安装依赖(可能本项目引入了新的依赖,或改变了依赖版本):
pip install -r requirements.txt
如果运行程序无报错,继续使用即可。如果此时运行报错,您可能还需要更新一部分依赖:
pip install -r requirements.txt --upgrade
- 最后,我们可能在
config_example.json中提供了新的配置项,您可以根据更新说明和下面的说明,调整您原有的config.json文件进行配置。
配置 config.json
这份表格列出了各配置项的基本情况与说明,具体细节可以点击链接查看。
| 配置项 | 可选值 | 说明 | 对应环境变量 |
|---|---|---|---|
"openai_api_key" |
(sk-xxxx) |
你的OpenAI API Key | OPENAI_API_KEY |
"google_palm_api_key" |
你的 Google PaLM API Key | GOOGLE_PALM_API_KEY |
|
"xmchat_api_key" |
(mil-xxx) |
你的 XMChat API Key | XMCHAT_API_KEY |
"minimax_api_key" |
你的 MiniMax API Key | MINIMAX_API_KEY |
|
"minimax_group_id" |
你的 MiniMax Group ID | MINIMAX_GROUP_ID |
|
"openai_api_type" |
"openai", "azure" |
若使用 azure 的 openai api key,请将该配置项设为"azure",并填写下面的azure配置 |
N/A |
"azure_openai_api_key"* |
你的 Azure OpenAI API Key,用于 Azure OpenAI 对话模型 | N/A | |
"azure_openai_api_base_url"* |
你的 Azure Base URL | N/A | |
"azure_openai_api_version"* |
("2023-05-15") |
你的 Azure OpenAI API 版本 | N/A |
"azure_deployment_name"* |
你的 Azure OpenAI Chat 模型 Deployment 名称 | N/A | |
"azure_embedding_deployment_name"* |
你的 Azure OpenAI Embedding 模型 Deployment 名称 | N/A | |
"azure_embedding_model_name"* |
("text-embedding-ada-002") |
你的 Azure OpenAI Embedding 模型名称 | N/A |
"language" |
"auto", "zh_CN", "en_US", "ja_JP", "ko_KR" |
设置语言 | LANGUAGUE |
"users"* |
设置用户登录密码 | N/A | |
"local_embedding" |
Bool | 是否在本地编制索引 | N/A |
"hide_history_when_not_logged_in" |
Bool | 未登录时隐藏历史对话记录 | N/A |
"check_update" |
Bool | 配置检查更新 | N/A |
"default_model" |
String | 默认使用的模型 | N/A |
"bot_avatar" |
"none", "default", (URL) |
语言模型头像,见配置头像 | N/A |
"user_avatar" |
"none", "default", (URL) |
用户头像,见配置头像 | N/A |
"default_chuanhu_assistant_model" |
川虎助手使用的模型,见 使用川虎助理与川虎助理pro | N/A | |
"GOOGLE_CSE_ID" |
见 使用川虎助理与川虎助理pro | N/A | |
"GOOGLE_API_KEY" |
见 使用川虎助理与川虎助理pro | N/A | |
"WOLFRAM_ALPHA_APPID" |
见 使用川虎助理与川虎助理pro | N/A | |
"SERPAPI_API_KEY" |
见 使用川虎助理与川虎助理pro | N/A | |
"show_api_billing" |
Bool | 是否显示 OpenAI API用量,见 额度显示 | SHOW_API_BILLING |
"sensitive_id" |
(sess-xxxx) |
你的OpenAI sensitive id,见 额度显示 | SENSITIVE_ID |
"usage_limit" |
Num | API Key的当月限额,见 额度显示 | USAGE_LIMIT |
"legacy_api_usage" |
Bool | 是否使用旧版 API 用量查询接口(OpenAI现已关闭该接口,但是如果你在使用第三方 API,第三方可能仍然支持此接口),见 额度显示 | |
"latex_option" |
"default", "strict", "all", "disabled" |
设置LaTeX渲染参数 | N/A |
"advance_docs"–"pdf"–"two_column" |
Bool | 是否默认认为PDF是双栏的 | N/A |
"multi_api_key"* |
Bool | 是否多个API Key轮换使用 | N/A |
"api_key_list"* |
用于轮换使用的多个API Key | N/A | |
"openai_api_base"* |
你希望使用的OpenAI API的基础URL | OPENAI_API_BASE |
|
"https_proxy"* |
你希望使用的代理 | HTTPS_PROXY |
|
"http_proxy"* |
你希望使用的代理 | HTTP_PROXY |
|
"server_name"* |
自定义ip | N/A | |
"server_port"* |
自定义端口 | N/A | |
"share"* |
Bool | 是否使用gradio创建公网分享链接 | N/A |
"available_models"* |
List[String] | 可用的模型列表,将覆盖默认的可用模型列表 | N/A |
"extra_models"* |
List[String] | 额外的模型,将添加到可用的模型列表之后 | N/A |
(表格中,标注星号(*)的为可选配置项,括号(())内的配置可选值为示例。)
设置用户登录密码
在config.json文件中的user字段,按照[[用户名1, 密码1], [用户名2, 密码2], [用户名3, 密码3], ...]的方式设定多个用户。
多用户示例:
{
...
"users": [
["admin", "p@ssW0rd"],
["nobody", "123456"]
],
...
}
单个用户示例:
{
...
"users": [["openai", "isCloseAi"]],
...
}
若不设置用户名与密码,可以直接将"users"字段整段删去,或留空设置为:
{
...
"users": [],
...
}
设置语言
{
...
"language": "auto",
...
}
"auto": 自动检测系统环境语言"zh_CN": 中文"en_US": English"ja_JP": 日本語"ko_KR": 한국어
Note
We would greatly appreciate it if you could help contribute a translation. Please refer to Localization page for more information.
配置头像
{
...
"bot_avatar": "default",
"user_avatar": "default",
...
}
"none": 不显示头像,仅有对话气泡"default": 显示默认头像。注意,如果该配置项空缺,也会显示默认头像- (URL): 显示自定义头像。可接受的URL包括网络地址,本地文件地址(需要存放在项目文件夹下,并正确配置路径)。
以及Data URL(如以base64编码的图片)——(20230830版本移除了Data URL支持)
示例:
{
...
"bot_avatar": "none",
"user_avatar": "https://www.apple.com.cn/leadership/images/overview/ceo_image.jpg",
...
}
未登录时隐藏历史对话记录
{
...
"hide_history_when_not_logged_in": true
...
}
true: 未登录时隐藏历史对话记录false: 未登录时显示历史对话记录(默认值)
如果多人使用,我们更建议您为每个用户分别设置用户名和登录密码,此时每个用户的历史记录是独立的,不会相互影响,能够较好地保护隐私。
如果您不想设置用户名和密码,可以将 "hide_history_when_not_logged_in" 设置为 true,这样将不再展示对话历史记录列表。不过,对于多人使用,我们并不推荐这种方法。
设置 LaTeX 渲染参数
- 从 20230709 版本开始,您可以在
config.json中设定 LaTeX 的渲染参数:{ ... "latex_option": "default", // latex 公式显示方式,可选"default", "strict", "all"或者"disabled" ... }
default: 渲染$...$或\(...\)形式的行内代码,渲染$$...$$或\[...\]形式的行间代码(默认值);strict: 在 default 基础上禁用$...$渲染行间代码;all: 在 default 基础上还支持渲染\begin{equation}...\end{equation}、\begin{align}...\end{equation}等环境;disabled: 不渲染任何形式的 LaTeX 公式。
-
在 20230614 至 20230628 版本中,因为 gradio 的更新,默认渲染LaTeX,且不再提供关闭选项。
-
在 20230601 以及更早的版本中,您可以在
config.json中设定是否开启LaTeX渲染。默认开启。
使用 川虎助理 与 川虎助理Pro
川虎助理(Pro) 经过特殊配置,可以达到类似 Auto-GPT 与 ChatGPT Browser 的效果。在模型列表中选择之后,就可以让它帮你上网查资料、去Arxiv上翻论文、用Wolfram解方程,等等。
- 川虎助理 能够检索互联网信息,但能力有限。
- 川虎助理Pro 会调用 谷歌自定义搜索引擎、SerpApi 与 Wolfram Alpha 的API,以达到更好的效果。
您需要自行申请并在config.json中按照注释填写这些 API Key。 - 相比 GPT-3.5,设置川虎助理使用 GPT-4 可以达到更好的效果。
{
...
"default_chuanhu_assistant_model": "gpt-4", //川虎助理使用的模型,可选gpt-3.5-turbo或者gpt-4
"GOOGLE_CSE_ID": "", //谷歌搜索引擎ID,用于川虎助理Pro模式,获取方式请看 https://stackoverflow.com/questions/37083058/programmatically-searching-google-in-python-using-custom-search
"GOOGLE_API_KEY": "", //谷歌API Key,用于川虎助理Pro模式
"WOLFRAM_ALPHA_APPID": "", //Wolfram Alpha API Key,用于川虎助理Pro模式,获取方式请看 https://products.wolframalpha.com/api/
"SERPAPI_API_KEY": "", //SerpAPI API Key,用于川虎助理Pro模式,获取方式请看 https://serpapi.com/
...
}
注意,使用自主运行模型会耗费大量token,尤其当您使用GPT-4作为基准模型时,可能会产生相当昂贵的花销。请您务必监控和管理自己的token使用和相关成本,防止意外收费。
使用 XMChat
- 通过等候列表提交试用申请
- 部署 川虎Chat 后在模型列表中选择 XMChat,并填入您的 XMChat API-Key
- 在“上传索引文件”栏中上传图片,等待图片上传完成后,即可开始聊天。
使用 MiniMax
谢谢你,@noahzark! (#774)
- 申请 MiniMax API。
- 从 MiniMax 获取 API Key(不包含"Bearer "前缀)和 Group ID,填写在
config.json中。 - 现在你可以使用 MiniMax 了!支持对话、System Prompt、调节常见参数(n_choices, max_generation_token, top_p, temperature)
使用本地 LLM 模型
以下的介绍默认您对计算机与环境配置有一定了解。这里以本地部署为例进行介绍。
部署并使用本地大语言模型进行对话对计算机配置有比较高的要求。您可以到每个开源模型的Github介绍页查看具体的最低配置。一般而言,若要使用本功能,您可能至少需要:
- 20GB 或更多磁盘空间(下载模型时请确保您有足够的磁盘空间)
- 8GB 或更高的GPU显存(某些模型可能需要在专业图形卡上运行)
如果您使用Windows,请通过 WSL 在 Linux 上安装 川虎Chat,否则很可能无法正常安装 DeepSpeed 等多个依赖。
配置环境
为了避免该项目与您的其他机器学习项目环境冲突,我们建议首先创建一个虚拟环境(您需要先安装 Anaconda 或 Miniconda):
conda create -n ChuanhuChat python=3.10
conda activate ChuanhuChat
然后,安装依赖:
pip install -r requirements.txt
pip install -r requirements_advanced.txt
下载与安装可能会持续比较久的时间,您需要确保网络状态的稳定。
另外,一般而言,如果您准备使用 GPU 运行这些大语言模型,您还应当安装CUDA Toolkit。
下载模型
如果环境顺利配置,您现在应当能成功在浏览器中启动 川虎Chat。不过,大语言模型必须先加载到您的计算机本地才能使用。
为方便用户使用,我们提供了自动下载模型的功能。当您在模型下拉列表中选取大语言模型时,程序将自动从对应的Hugging Face模型仓库中下载模型文件,这些模型将会被存储在 ~/.cache/huggingface 文件夹中。
- 默认自动下载的 StableLM 模型为 StableLM-Tuned-Alpha-7B
- 默认自动下载的 MOSS 模型为 MOSS-Moon-003-SFT
您也可以手动下载并管理模型文件。首先确保您已经安装 git-lfs。我们默认您的终端位于项目文件夹。
cd models
git lfs install
git clone <model repository>
对应具体的大语言模型,第三行可以被分别替换为:
- ChatGLM
- ChatGLM-6B
git clone https://huggingface.co/THUDM/chatglm-6b - ChatGLM-6B-INT8
git clone https://huggingface.co/THUDM/chatglm-6b-int8 - ChatGLM-6B-INT4
git clone https://huggingface.co/THUDM/chatglm-6b-int4
- ChatGLM-6B
- ChatGLM2
- ChatGLM2-6B
git clone https://huggingface.co/THUDM/chatglm2-6b - ChatGLM2-6B-INT4
git clone https://huggingface.co/THUDM/chatglm2-6b-int4 - ChatGLM2-6B-32K
git clone https://huggingface.co/THUDM/chatglm2-6b-32k - ChatGLM2-6B-32K-INT4
git clone https://huggingface.co/THUDM/chatglm2-6b-32k-int4
- ChatGLM2-6B
- StableLM
- StableLM-Base-Alpha-3B
git clone https://huggingface.co/stabilityai/stablelm-base-alpha-3b - StableLM-Base-Alpha-7B
git clone https://huggingface.co/stabilityai/stablelm-base-alpha-7b - StableLM-Tuned-Alpha-3B
git clone https://huggingface.co/stabilityai/stablelm-tuned-alpha-3b - StableLM-Tuned-Alpha-7B
git clone https://huggingface.co/stabilityai/stablelm-tuned-alpha-7b
- StableLM-Base-Alpha-3B
- LLaMA
- LLaMA-7B-HF
git clone https://huggingface.co/decapoda-research/llama-7b-hf - LLaMA-13B-HF
git clone https://huggingface.co/decapoda-research/llama-13b-hf - LLaMA-33B-HF
git clone https://huggingface.co/decapoda-research/llama-33b-hf - LLaMA-65B-HF
git clone https://huggingface.co/decapoda-research/llama-65b-hf
- LLaMA-7B-HF
- MOSS
- MOSS-Moon-003-Base
git clone https://huggingface.co/fnlp/moss-moon-003-base - MOSS-Moon-003-SFT
git clone https://huggingface.co/fnlp/moss-moon-003-sft - MOSS-Moon-003-SFT-Plugin
git clone https://huggingface.co/fnlp/moss-moon-003-sft-plugin
- MOSS-Moon-003-Base
对于 LLaMA 模型,您还可以手动下载微调的 LoRA 模型,只要将模型文件夹放置在本项目的 lora 文件夹下即可。
- 这里提供了一些 LoRA 模型。
- 当然,您还可以使用其他开源的 LoRA 模型,如 Baize-lora-7B,甚至是您自己训练的LoRA模型~
故障排除
./build_bundled.sh: Line 19: cmake: command not found
- 需要先安装CMake。
RuntimeError: Library cudart is not initialized
Tokenizer class LLaMATokenizer does not exist or is not currently imported.
- 参见:#655
Failed to connect to github.com port 443 after xxxx ms
- 需要使用一些手段使你能稳定连接github。如果你使用WSL,注意WSL的网络可能也需要特殊配置使其能稳定连接github。
功能说明
额度显示
2023年7月起,OpenAI 再次更改了余额查询的相关接口,需要在请求头中包含用户当期登录 session 的 Sensitive_ID 才能查询到余额。由于获取 Sensitive_ID 较为复杂同时不够稳定,我们默认关闭了余额显示功能。
如果您在使用OpenAI官方API,且希望使用额度显示功能,请首先将 show_api_billing 设置为 true:
{
...
"show_api_billing": true,
"sensitive_id": "sess-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"legacy_api_usage": false,
...
}
并在 config.json 中填写您本次登录的 Sensitive_ID,其格式类似于: sess-xxxxx。
如果您需要在 Hugging Face 的 Space 中设置,对应的 Secret 为 SENSITIVE_ID。
获取 Sensitive_ID 的方法为:
- 打开浏览器,前往 https://platform.openai.com/,使用你的 OpenAI 账号登录(如果已经登录,需要注销后重新登录)
- 按下F12,打开开发者工具(如果你使用 Safari,可以右键选择
检查元素) - 打开 Network(网络)选项卡,筛选
Fetch/XHR,选择login页面 - 查看其中的 Response(响应)信息,复制其中 sensitive_id 对应的值

需要注意的是,一次获取的sensitive id只对当期登录session有效,一旦退出重新登录,原先的sensitive id就无法再用于查询用量,必须使用重新登录时新生成的sensitive id才有效。
不过,如果你在使用第三方 API,第三方可能仍然支持使用老接口获取用量,此时你不必填写Sensitive_ID,只需要将 legacy_api_usage 设置为 true 即可:
{
...
"show_api_billing": true,
"sensitive_id": "",
"legacy_api_usage": true,
...
}
另外,你还可以在 config.json 中设定额度上限。单位为美元,默认值为120。
{
...
"usage_limit": 20,
...
}
模型选择
ChatGPT
这里的数据来自 OpenAI 的理论值,不过,实际体验可能被限制,某些模型可能无法调用。
| LATEST MODEL | DESCRIPTION | MAX TOKENS | TRAINING DATA |
|---|---|---|---|
| gpt-3.5-turbo | Most capable GPT-3.5 model and optimized for chat at 1/10th the cost of text-davinci-003. Will be updated with our latest model iteration. | 4,096 tokens | Up to Sep 2021 |
| gpt-3.5-turbo-0301 | Snapshot of gpt-3.5-turbo from March 1st 2023. Unlike gpt-3.5-turbo, this model will not receive updates, and will be deprecated 3 months after a new version is released. | 4,096 tokens | Up to Sep 2021 |
| gpt-4 | More capable than any GPT-3.5 model, able to do more complex tasks, and optimized for chat. Will be updated with our latest model iteration. | 8,192 tokens | Up to Sep 2021 |
| gpt-4-0314 | Snapshot of gpt-4 from March 14th 2023. Unlike gpt-4, this model will not receive updates, and will be deprecated 3 months after a new version is released. | 8,192 tokens | Up to Sep 2021 |
| gpt-4-32k | Same capabilities as the base gpt-4 mode but with 4x the context length. Will be updated with our latest model iteration. | 32,768 tokens | Up to Sep 2021 |
| gpt-4-32k-0314 | Snapshot of gpt-4-32 from March 14th 2023. Unlike gpt-4-32k, this model will not receive updates, and will be deprecated 3 months after a new version is released. | 32,768 tokens | Up to Sep 2021 |
本地大模型
详见:使用本地 LLM 大模型。
实时传输回答
| 开启实时传输回答 | 关闭实时传输回答 |
|---|---|
单轮对话
勾选“单轮对话”后,模型将不记住上下文对话,仅对您本次发送的内容进行回复。
联网搜索回答
需要勾选“使用在线搜索”。
启用后,将使用 Google 或 Duckduckgo 检索网络信息再返回回答,能达到类似于 New Bing 的效果。视能检索到的互联网信息的丰富与准确与否,回答效果较原来可能有所提升。
由于搜索引擎公司的反爬虫技术,这项功能可能不够稳定。如有更多需要联网信息的需要,可以使用川虎助理。
该功能可能需要耗费更多的token。
根据文件回答
需要先在“模型”选项卡的“上传”区上传文件。支持 PDF、txt、docx 等格式。
上传后,将对本地文件进行索引,模型将针对文件内容进行回答。当您已经上传并索引完成一个文件后,且您没用清除本项目的缓存,若您在之后重新试图上传该文件,本程序将自动寻找并使用之前的索引,不会重复索引。
索引功能可能需要耗费更多的token。
选择回复语言(针对搜索&索引功能)
需要注意,回复语言的选择只针对联网搜索和根据文件回答功能,普通的对话并不能设定回复语言(除非您在System Prompt中自己写入)。
对话气泡按钮
![]() 和
和![]() 用于在模型原始输出文本和markdown渲染文本之间切换。
用于在模型原始输出文本和markdown渲染文本之间切换。
![]() 用于复制本条对话模型输出的原始文本。
用于复制本条对话模型输出的原始文本。
微调 GPT 3.5
准备数据集
数据集需要为符合 OpenAI 要求 的 .jsonl 格式或者 Excel .xlsx格式。Excel 的格式要求为:
- 表头(第一行)为
提问、答案和可选的系统。这三个的顺序不影响什么,但一个字都不能改。 - 提问就是用户提问,答案就是预期 GPT 的回答,系统就是训练时使用的 System Prompt。
也就是说,Excel 的格式为:
| 提问 | 答案 | 系统 |
|---|---|---|
| 回答 1 | 答案 1 | 系统 Prompt |
| 回答 2 | 答案 2 | 系统 Prompt |
| ... | ... | ... |
OpenAI 要求至少需要 10 条这样的示例问答才能开始训练。当然,越多越好。但是长度需要在 4096 token 以内。在浏览器里上传文件之后,可以看到数据集预览,也就是第一条数据。然后,点击上传到OpenAI按钮上传到OpenAI 服务器。
开始训练
文件 ID 在上传后会自动填充,或者你可以保存下来,以后粘贴到这里就行,而无需重复上传数据集。模型名称后缀会出现在最终的模型名称里。训练轮数越多,效果通常越好,但是开销也更高。点击“开始训练”,就可以将任务加入 OpenAI 的队列。训练完成之后,你会收到邮件通知。
状态
在这里,你可以管理你的训练队列。比如,获取当前所有成功和正在进行的任务,取消正在训练的任务,将训练完成的模型加入川虎 Chat 的模型列表等。

